Théorèmes limites pour les variables aléatoires
De nombreuses situations pratiques impliquent des variables aléatoires définies comme la somme ou la moyenne d'autres variables aléatoires. Par exemple, l'estimation de la moyenne d'une population à partir de la moyenne d'un échantillon repose fortement sur les propriétés de ces sommes. Les théorèmes limites fournissent la base mathématique de ce type d'estimations.
Les théorèmes limites sont des résultats fondamentaux en théorie des probabilités qui décrivent le comportement des sommes de variables aléatoires lorsque le nombre de termes augmente. Nous nous concentrerons sur deux théorèmes essentiels :
Les théorèmes limites sont des résultats fondamentaux en théorie des probabilités qui décrivent le comportement des sommes de variables aléatoires lorsque le nombre de termes augmente. Nous nous concentrerons sur deux théorèmes essentiels :
- La loi des grands nombres (LGN) : ce théorème explique pourquoi les moyennes se stabilisent. Il affirme que lorsque l'on répète une expérience un grand nombre de fois, la moyenne des résultats (moyenne expérimentale) se rapproche de plus en plus de l'espérance (moyenne théorique).
- Le théorème central limite (TCL) : ce théorème explique la forme de la distribution. Il affirme que si l'on additionne un grand nombre de variables aléatoires indépendantes, la distribution de leur somme (ou de leur moyenne) tend vers une loi normale, quelle que soit la distribution d'origine des variables (sous certaines hypothèses techniques).
- La probabilité expérimentale (ou fréquence observée) se rapproche-t-elle de la probabilité théorique lorsque le nombre d'essais augmente ? Oui, la loi des grands nombres le garantit.
- Pouvons-nous quantifier l'erreur entre notre estimation par échantillonnage et la vraie valeur ? Oui, le théorème central limite permet de définir des intervalles de confiance et des marges d'erreur à l'aide de la loi normale.
Combinaison linéaire de variables aléatoires
Considérons le lancer d'une pièce équilibrée deux fois. Les variables aléatoires \(X_1\) et \(X_2\) représentent respectivement le résultat du premier et du second lancer. On code le succès (Face) par 1 et l'échec (Pile) par 0. On suppose les deux lancers indépendants.
Ainsi, \(X_1\) et \(X_2\) suivent une loi de Bernoulli de paramètre \(p=\dfrac{1}{2}\). Nous nous intéressons à deux nouvelles variables aléatoires :
Ainsi, \(X_1\) et \(X_2\) suivent une loi de Bernoulli de paramètre \(p=\dfrac{1}{2}\). Nous nous intéressons à deux nouvelles variables aléatoires :
- \(S_2 = X_1 + X_2\) : le nombre total de faces.
- \(\overline{X}_2 = \dfrac{X_1 + X_2}{2}\) : la proportion moyenne de faces.
- Distribution de probabilité : on peut visualiser les issues à l'aide d'un arbre de probabilité.
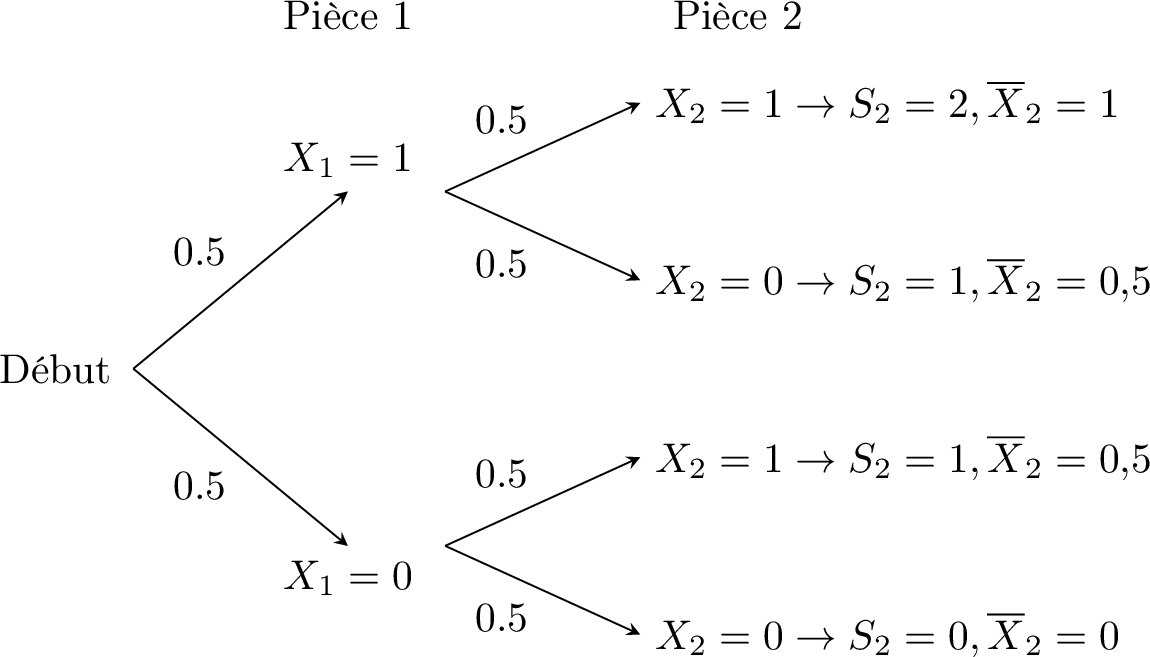
\quad\(s\) (somme) \(0\) \(1\) \(2\) \(P(S_2=s)\) \(1/4\) \(1/2\) \(1/4\) \(\bar{x}\) (moyenne) \(0\) \(0{,}5\) \(1\) \(P(\overline{X}_2=\bar{x})\) \(1/4\) \(1/2\) \(1/4\) - Espérance :$$E(S_2) = 0\left(\tfrac{1}{4}\right) + 1\left(\tfrac{1}{2}\right) + 2\left(\tfrac{1}{4}\right) = 1,$$$$E(\overline{X}_2) = 0\left(\tfrac{1}{4}\right) + 0{,}5\left(\tfrac{1}{2}\right) + 1\left(\tfrac{1}{4}\right) = 0{,}5.$$
- Lien avec les variables individuelles :
Comme \(E(X_1) = E(X_2) = p = 0{,}5\), on obtient :$$E(S_2) = 1 = 2 \times 0{,}5 = 2E(X_1),$$$$E(\overline{X}_2) = 0{,}5 = E(X_1).$$ - Variance :$$V(S_2) = (0-1)^2\left(\tfrac{1}{4}\right) + (1-1)^2\left(\tfrac{1}{2}\right) + (2-1)^2\left(\tfrac{1}{4}\right) = \tfrac{1}{4} + 0 + \tfrac{1}{4} = 0{,}5,$$$$V(\overline{X}_2) = (0-0{,}5)^2\left(\tfrac{1}{4}\right) + (0{,}5-0{,}5)^2\left(\tfrac{1}{2}\right) + (1-0{,}5)^2\left(\tfrac{1}{4}\right) = \tfrac{0{,}25}{4} + 0 + \tfrac{0{,}25}{4} = 0{,}125.$$
- Lien avec la variance individuelle :
Comme \(V(X_1) = p(1-p) = 0{,}25\), on a :$$V(S_2) = 0{,}5 = 2 \times 0{,}25 = 2V(X_1),$$$$V(\overline{X}_2) = 0{,}125 = \dfrac{0{,}25}{2} = \dfrac{V(X_1)}{2}.$$
Définition Combinaison linéaire de variables aléatoires
Une combinaison linéaire de variables aléatoires \(X_1, X_2, \ldots, X_n\) est une nouvelle variable aléatoire \(Y\) définie par$$ Y = a_1 X_1 + a_2 X_2 + \ldots + a_n X_n, $$où \(a_1, a_2, \ldots, a_n\) sont des coefficients constants.
Définition Somme et moyenne de variables aléatoires
Étant donné \(n\) variables aléatoires \(X_1, X_2, \dots, X_n\) :
- La somme est notée \(S_n = X_1 + X_2 + \ldots + X_n\).
- La moyenne d'échantillon est notée \(\overline{X}_n = \dfrac{X_1 + X_2 + \ldots + X_n}{n}\).
Proposition Propriétés de l'espérance et de la variance
Pour des variables aléatoires \(X_1, \dots, X_n\) et des constantes \(a_1, \dots, a_n\) :
- L'espérance est linéaire : $$ E\left(\sum_{i=1}^n a_i X_i\right) = \sum_{i=1}^n a_i E(X_i). $$
- La variance s'additionne pour des variables indépendantes : si \(X_1, \dots, X_n\) sont indépendantes, $$ V\left(\sum_{i=1}^n a_i X_i\right) = \sum_{i=1}^n a_i^2 V(X_i). $$
Proposition Espérance des sommes et des moyennes
Si \(X_1, X_2, \dots, X_n\) sont identiquement distribuées avec une moyenne \(\mu\), alors :$$ E(S_n) = n\mu \qquad\text{et}\qquad E(\overline{X}_n) = \mu. $$
- Pour la somme \(S_n\) :
En utilisant la linéarité de l'espérance :$$ \begin{aligned}E(S_n) &= E(X_1 + X_2 + \dots + X_n) \\ &= E(X_1) + E(X_2) + \dots + E(X_n) \\ &= \mu + \mu + \dots + \mu \quad \text{(\(n\) fois)} \\ &= n\mu.\end{aligned} $$ - Pour la moyenne \(\overline{X}_n\) :
En utilisant \(E(aX) = aE(X)\) :$$ \begin{aligned}E(\overline{X}_n) &= E\left(\frac{S_n}{n}\right) \\ &= \frac{1}{n} E(S_n) \\ &= \frac{1}{n} (n\mu) \\ &= \mu.\end{aligned} $$
Exemple
Soient \(X_1, \dots, X_9\) des variables aléatoires de moyenne \(\mu=5\). Déterminer l'espérance de leur somme \(S_9\).
$$ E(S_9) = 9 \times \mu = 9 \times 5 = 45. $$
Proposition Variance des sommes et des moyennes
Si \(X_1, X_2, \dots, X_n\) sont indépendantes et identiquement distribuées avec une variance \(\sigma^2\) (et un écart-type \(\sigma\)), alors :
- Pour la somme : $$ V(S_n) = n\sigma^2 \quad \text{et} \quad \sigma(S_n) = \sigma\sqrt{n}; $$
- Pour la moyenne : $$ V(\overline{X}_n) = \frac{\sigma^2}{n} \quad \text{et} \quad \sigma(\overline{X}_n) = \frac{\sigma}{\sqrt{n}}. $$
- Pour la somme \(S_n\) :
Puisque les variables \(X_1, \dots, X_n\) sont indépendantes, la variance de la somme est la somme des variances :$$ \begin{aligned}V(S_n) &= V(X_1 + X_2 + \dots + X_n) \\ &= V(X_1) + V(X_2) + \dots + V(X_n) \\ &= \sigma^2 + \sigma^2 + \dots + \sigma^2 \quad \text{(\(n\) fois)} \\ &= n\sigma^2.\end{aligned} $$L'écart-type est la racine carrée de la variance :$$ \sigma(S_n) = \sqrt{V(S_n)} = \sqrt{n\sigma^2} = \sigma\sqrt{n}. $$ - Pour la moyenne \(\overline{X}_n\) :
En utilisant la propriété \(V(aX) = a^2V(X)\) avec \(a = \dfrac{1}{n}\) :$$ \begin{aligned}V(\overline{X}_n) &= V\left(\frac{S_n}{n}\right) \\ &= \left(\frac{1}{n}\right)^2 V(S_n) \\ &= \frac{1}{n^2} (n\sigma^2) \\ &= \frac{\sigma^2}{n}.\end{aligned} $$On en déduit :$$ \sigma(\overline{X}_n) = \sqrt{V(\overline{X}_n)} = \sqrt{\frac{\sigma^2}{n}} = \frac{\sigma}{\sqrt{n}}. $$
Exemple Proportion d'échantillon
Des articles sortant d'une chaîne de montage sont défectueux avec une probabilité \(p\). On définit pour chaque article une variable indicatrice \(X_i\) telle que \(X_i=1\) si le \(i\)-ème article est défectueux et \(0\) sinon. La variable \(X_i\) suit une loi de Bernoulli. Déterminer la moyenne et l'écart-type de la proportion d'échantillon \(\overline{X}_n\).
Pour une variable de Bernoulli, on a \(\mu = p\) et \(\sigma = \sqrt{p(1-p)}\). Par conséquent, pour la moyenne d'échantillon \(\overline{X}_n\) :$$ E(\overline{X}_n) = p, $$$$ \sigma(\overline{X}_n) = \frac{\sigma}{\sqrt{n}} = \sqrt{\frac{p(1-p)}{n}}. $$
Loi des grands nombres
La loi des grands nombres (LGN) décrit le résultat de la répétition d'une même expérience un grand nombre de fois. Elle affirme que la moyenne des résultats obtenus sur de nombreux essais doit être proche de la valeur attendue et qu'elle tend à s'en rapprocher à mesure que le nombre d'essais augmente.
En pratique, cela justifie notre intuition selon laquelle la probabilité expérimentale estime la probabilité théorique. À court terme, les résultats sont imprévisibles (par exemple, un casino peut perdre de l'argent sur quelques tours), mais à long terme les moyennes sont très prévisibles (sur la durée, le casino gagne).
En pratique, cela justifie notre intuition selon laquelle la probabilité expérimentale estime la probabilité théorique. À court terme, les résultats sont imprévisibles (par exemple, un casino peut perdre de l'argent sur quelques tours), mais à long terme les moyennes sont très prévisibles (sur la durée, le casino gagne).
Définition Moyenne limite
Lorsque la limite existe, on note \(\overline{X}_\infty\) la limite de la moyenne d'échantillon lorsque \(n\) tend vers l'infini :$$ \overline{X}_\infty = \lim_{n\to\infty} \overline{X}_n. $$
Theorem Loi des grands nombres
Pour des variables aléatoires indépendantes et identiquement distribuées \(X_1, X_2, \dots\) de moyenne \(\mu\) et d'écart-type \(\sigma\), la moyenne d'échantillon converge vers la moyenne de la population lorsque le nombre d'observations tend vers l'infini. En notation plus avancée,$$ P\!\big(\overline{X}_\infty = \mu\big) = 1. $$Cela signifie que la moyenne de l'échantillon converge vers la moyenne de la population avec une certitude au sens probabiliste.
Rappelons que la variance de la moyenne d'échantillon est$$ V(\overline{X}_n) = \frac{\sigma^2}{n}. $$Lorsque \(n \to \infty\), le terme \(\dfrac{\sigma^2}{n}\) tend vers \(0\).
Une variable aléatoire de variance nulle n'a pas de dispersion : elle est presque sûrement constante. Ainsi, lorsque \(n\) augmente, la distribution de \(\overline{X}_n\) se concentre de plus en plus autour de son espérance \(\mu\), et, dans la limite, elle se réduit à cette valeur unique.
Une variable aléatoire de variance nulle n'a pas de dispersion : elle est presque sûrement constante. Ainsi, lorsque \(n\) augmente, la distribution de \(\overline{X}_n\) se concentre de plus en plus autour de son espérance \(\mu\), et, dans la limite, elle se réduit à cette valeur unique.
La distribution limite est déterministe : dans la limite, la moyenne d'échantillon prend la valeur \(\mu\) avec une probabilité égale à \(1\).
Exemple Probabilité expérimentale vs théorique
Considérons le lancer d'un cône. La probabilité \(p\) qu'il retombe sur sa base n'est pas connue a priori.
En pratique, nous ne pouvons jamais répéter une expérience un nombre infini de fois. La moyenne d'échantillon reste donc une approximation de la vraie moyenne. Le théorème suivant, le théorème central limite, permet de quantifier l'erreur de cette approximation et de décrire la façon dont la moyenne d'échantillon fluctue autour de \(\mu\) pour des valeurs de \(n\) grandes mais finies.
Théorème central limite
Le théorème central limite (TCL) est l'un des résultats les plus remarquables des mathématiques. De manière informelle, il affirme que si l'on prend un échantillon de taille suffisamment grande dans une population ayant n'importe quelle distribution (pas nécessairement normale), alors la distribution de la moyenne d'échantillon (ou de la somme) est approximativement normale.
Cette approximation normale justifie l'utilisation systématique de la loi normale pour construire des intervalles de confiance et réaliser des tests d'hypothèses, même lorsque la population de départ n'est pas elle-même normale.
Cette approximation normale justifie l'utilisation systématique de la loi normale pour construire des intervalles de confiance et réaliser des tests d'hypothèses, même lorsque la population de départ n'est pas elle-même normale.
Proposition Somme et moyenne de variables normales
Si \(X_1, \dots, X_n\) sont indépendantes et suivent une loi normale de moyenne \(\mu\) et d'écart-type \(\sigma\), alors :
- La somme \(S_n\) suit exactement une loi normale de moyenne \(n\mu\) et de variance \(n\sigma^2\) : $$ S_n \sim N(n\mu, n\sigma^2). $$
- La moyenne d'échantillon \(\overline{X}_n\) suit exactement une loi normale de moyenne \(\mu\) et de variance \(\dfrac{\sigma^2}{n}\) : $$ \overline{X}_n \sim N\!\left(\mu, \frac{\sigma^2}{n}\right). $$
Exemple
Soient \(X_1, \dots, X_5\) des variables aléatoires suivant une loi normale de moyenne \(90\) et d'écart-type \(20\).
- La moyenne \(\overline{X}_5\) suit-elle une loi normale ?
- Calculer \(P(80 \leqslant \overline{X}_5 \leqslant 100)\).
- Oui, car toute combinaison linéaire de variables normales est normale. En particulier, la moyenne \(\overline{X}_5\) suit une loi normale.
- La moyenne de \(\overline{X}_5\) est \(E(\overline{X}_5) = 90\). Son écart-type est $$ \sigma(\overline{X}_5) = \frac{20}{\sqrt{5}} \approx 8{,}94. $$ À l'aide d'une calculatrice pour la loi \(N(90; 8{,}94^2)\), on obtient : $$P(80 \leqslant \overline{X}_5 \leqslant 100) \approx 0{,}737.$$
Proposition Moyenne standardisée
Pour \(n\) variables aléatoires indépendantes de moyenne commune \(\mu\) et d'écart-type \(\sigma\), la moyenne d'échantillon \(\overline{X}_n\) vérifie$$ E(\overline{X}_n) = \mu, \qquad \sigma(\overline{X}_n) = \frac{\sigma}{\sqrt{n}}. $$La variable standardisée$$ Z_n = \frac{\overline{X}_n - \mu}{\sigma/\sqrt{n}} $$a une moyenne égale à \(0\) et un écart-type égal à \(1\).
On rappelle d'abord les propriétés de la moyenne d'échantillon \(\overline{X}_n\) :$$ E(\overline{X}_n) = \mu \quad \text{et} \quad \sigma(\overline{X}_n) = \frac{\sigma}{\sqrt{n}}. $$
- Moyenne de \(Z_n\) :
En utilisant la linéarité de l'espérance, \(E(aX+b) = aE(X)+b\) :$$ \begin{aligned}E(Z_n) &= E\left(\frac{\overline{X}_n - \mu}{\sigma/\sqrt{n}}\right) \\ &= \frac{1}{\sigma/\sqrt{n}} \left( E(\overline{X}_n) - \mu \right) \\ &= \frac{1}{\sigma/\sqrt{n}} (\mu - \mu) \\ &= 0.\end{aligned} $$ - Écart-type de \(Z_n\) :
En utilisant la propriété \(\sigma(aX+b) = |a|\sigma(X)\) :$$ \begin{aligned}\sigma(Z_n) &= \sigma\left(\frac{\overline{X}_n - \mu}{\sigma/\sqrt{n}}\right) \\ &= \frac{1}{\sigma/\sqrt{n}} \cdot \sigma(\overline{X}_n) \\ &= \frac{1}{\sigma/\sqrt{n}} \cdot \frac{\sigma}{\sqrt{n}} \\ &= 1.\end{aligned} $$
La puissance du théorème central limite apparaît particulièrement lorsque l'on part d'une distribution qui n'est pas normale. Par exemple, supposons que chaque \(X_i\) suive une distribution uniforme. Les figures ci-dessous montrent la densité de la somme (ou moyenne) standardisée \(Z_n\) pour des valeurs croissantes de \(n\).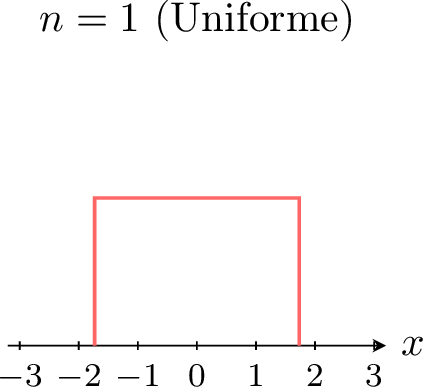 \(\quad\)
\(\quad\)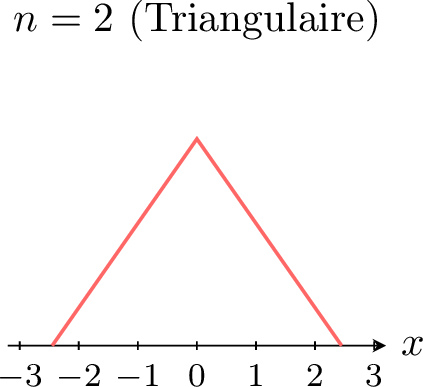 \(\quad\)
\(\quad\)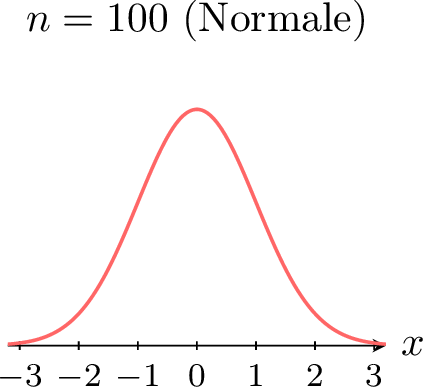
\(\quad\)\(\quad\)
Theorem Théorème central limite
Soient \(X_1, X_2, \dots, X_n\) des variables aléatoires indépendantes et identiquement distribuées de moyenne \(\mu\) et d'écart-type \(\sigma\). Si la taille de l'échantillon \(n\) est suffisamment grande (typiquement \(n \ge 30\)), alors :
- la moyenne d'échantillon \(\overline{X}_n\) est approximativement distribuée selon une loi normale : $$ \overline{X}_n \approx N\!\left(\mu, \frac{\sigma^2}{n}\right); $$
- la somme \(S_n\) est approximativement distribuée selon une loi normale : $$ S_n \approx N(n\mu, n\sigma^2); $$
- la variable standardisée $$ Z_n = \frac{\overline{X}_n - \mu}{\sigma/\sqrt{n}} $$ est, pour \(n\) grand, approximativement distribuée selon une loi normale standard \(N(0,1)\). Plus rigoureusement, la loi de \(Z_n\) converge vers \(N(0,1)\) lorsque \(n \to \infty\).
Exemple
Une population de variables aléatoires a une moyenne de \(174\) et un écart-type de \(6\). On prélève un échantillon de taille \(64\).
- La moyenne d'échantillon \(\overline{X}_{64}\) est-elle approximativement distribuée normalement ? Justifiez.
- Déterminer la moyenne et l'écart-type de \(\overline{X}_{64}\).
- Calculer la probabilité que la moyenne d'échantillon soit comprise entre \(172\) et \(176\).
- Oui. Comme la taille de l'échantillon vaut \(n=64\) (et que \(n \ge 30\)), le théorème central limite s'applique et la distribution d'échantillonnage de \(\overline{X}_{64}\) est approximativement normale.
- Moyenne et écart-type : $$ E(\overline{X}_{64}) = \mu = 174, $$ $$ \sigma(\overline{X}_{64}) = \frac{\sigma}{\sqrt{n}} = \frac{6}{\sqrt{64}} = \frac{6}{8} = 0{,}75. $$
- En utilisant une calculatrice pour la loi normale \(N(174; 0{,}75^2)\), on obtient : $$ P(172 \leqslant \overline{X}_{64} \leqslant 176) \approx 0{,}9923. $$