Statistiques
Processus d'enquête statistique
Une enquête étape par étape
Les statistiques sont partout autour de nous, des moyennes sportives aux bulletins d'information sur la météo.
- Un joueur de basket-ball marque en moyenne 14,6 points par match.
- L'année dernière a été l'année la plus chaude jamais enregistrée depuis 1897.
Définition Statistiques
Les statistiques sont la science qui consiste à concevoir des enquêtes, puis à collecter, organiser, analyser et interpréter des données pour répondre à une question spécifique.
Méthode Processus d'enquête statistique
Une enquête statistique rigoureuse suit ces cinq étapes clés :
- Poser la question : Définir un problème de recherche clair, en identifiant la population cible et les variables à étudier.
- Collecter les données : Concevoir un plan de collecte de données et recueillir des informations en utilisant une méthode d'échantillonnage appropriée.
- Analyser les données : Calculer les statistiques descriptives pertinentes pour résumer les données numériquement. Cela inclut le calcul des fréquences relatives (pourcentages), des mesures de tendance centrale (moyenne, médiane, mode) et des mesures de dispersion (écart-type, EIQ).
- Représenter les données : Structurer les données brutes dans des tableaux (par ex., un tableau d'effectifs montrant les comptes/bâtons) et créer des représentations visuelles initiales (par ex., histogrammes, diagrammes en bâtons) pour voir la distribution.
- Interpréter et conclure : Tirer des inférences de l'analyse, fournir une conclusion qui répond à la question initiale, et évaluer les limites de l'enquête.
Étape 1 : Poser la question
Concepts clés de l'enquête
Définition Problème statistique
Un problème statistique est une question claire et précise à laquelle on peut répondre en collectant et en analysant des données.
Exemple
Étudions le problème : « Quelle est la matière scolaire préférée des élèves de notre école ? »
Définition Population
Une population est l'ensemble complet de tous les individus, objets ou événements qui partagent une caractéristique commune et bien définie, objet d'une enquête statistique.
Exemple
Pour notre problème, la population est l'ensemble des élèves de notre école.
Définition Données
Les données sont l’ensemble des informations qu’on collecte, comme des chiffres, des mots, des mesures ou des observations.
Exemple
Les données que nous collectons seront la liste des réponses de chaque élève, comme « Maths », « Arts », « Sciences », « Arts », « Sport », etc.
Définition Types de variables
Une variable est une caractéristique d'un individu de la population qui peut prendre différentes valeurs. Les variables sont classées en deux types principaux :
- Variable qualitative (Catégorielle) : Représente des caractéristiques qui appartiennent à une catégorie ou à un groupe (ex: couleur des yeux, type de voiture, matière préférée).
- Variable quantitative (Numérique) : Représente des caractéristiques qui peuvent être comptées ou mesurées numériquement. Celles-ci peuvent être subdivisées en :
- Discrète : La variable ne peut prendre que des valeurs numériques spécifiques et distinctes (souvent des entiers). Ce sont généralement des données que l'on compte.
- Continue : La variable peut prendre n'importe quelle valeur numérique à l'intérieur d'un intervalle donné. Ce sont généralement des données que l'on mesure.
Exemple
Classifions quelques variables d'une enquête sur les élèves :
- La variable « Matière préférée » est qualitative.
- La variable « Nombre de frères et sœurs » est une variable quantitative discrète, car les réponses ne peuvent être que des nombres entiers (0, 1, 2, ...).
- La variable « Taille en centimètres » est une variable quantitative continue, car la taille d'un élève peut être n'importe quelle valeur dans un intervalle (par ex., 165,2 cm, 165,25 cm, etc.).
Conception de sondages et formulation des questions
L'objectif principal de la conception d'un sondage est de collecter des données à la fois valides (qui mesurent ce qu'elles sont censées mesurer) et fiables (cohérentes). La formulation des questions est essentielle pour y parvenir, car elle influe directement sur la qualité des données collectées et introduit ou minimise le risque de biais.
Définition Questions structurées (fermées)
Les questions structurées (ou fermées) proposent aux répondants une liste prédéfinie de réponses parmi lesquelles choisir.
- Avantages : Faciles à coder et à analyser statistiquement ; produisent des données quantitatives ou qualitatives aisément catégorisables.
- Inconvénients : Peuvent limiter l'expression de l'opinion réelle du répondant ; peuvent introduire un biais si les options sont mal conçues.
Définition Questions non structurées (ouvertes)
Les questions non structurées (ou ouvertes) permettent aux répondants de répondre avec leurs propres mots, fournissant des informations riches et détaillées.
- Avantages : Fournissent des informations qualitatives approfondies ; peuvent révéler des perspectives inattendues.
- Inconvénients : Difficiles et longues à analyser ; les réponses peuvent être difficiles à comparer et à quantifier.
Méthode Principes pour une conception de questions efficace
Pour minimiser les biais et garantir la qualité des données, les questions d'un sondage doivent respecter les principes suivants :
- Éviter l'ambiguïté et les questions doubles. Une question ne doit porter que sur un seul sujet (par exemple Éviter « Êtes-vous satisfait de la nourriture de la cantine et des horaires de la bibliothèque ? »).
- Éviter les formulations orientées ou biaisées. Les questions doivent être neutres et ne pas suggérer de « bonne » réponse (ex: Éviter « N’êtes-vous pas d’accord que la nouvelle politique environnementale est une excellente idée ? »).
- Assurer la clarté et la simplicité. Utiliser un langage facilement compréhensible par l'ensemble de la population de l'échantillon.
- Fournir des options mutuellement exclusives et exhaustives (pour les questions fermées). Les options ne doivent pas se chevaucher et toutes les réponses possibles doivent être couvertes (souvent en incluant une catégorie « Autre »).
Exemple
Après avoir identifié la matière préférée d'un élève, un enquêteur souhaite recueillir des informations plus détaillées. Comparez une question de suivi structurée et une question non structurée qu'il pourrait poser.
- Question de suivi non structurée : « Pourquoi cette matière est-elle ta préférée ? »
- Type de données : Cela produit des données qualitatives riches et ouvertes (par ex., « J'aime résoudre des problèmes », « Le professeur est inspirant », « Je me sens créatif »).
- Analyse : Ces données offrent des aperçus approfondis sur les raisons des préférences mais sont difficiles à quantifier ou à représenter graphiquement directement. Elles nécessitent une analyse thématique plutôt qu'un calcul numérique. »
- Question de suivi structurée : « Combien d'heures par semaine consacres-tu à ta matière préférée ?
- Type de données : Cela produit des données quantitatives. Les réponses sont numériques.
- Analyse : Ces données sont faciles à comptabiliser et à visualiser dans un histogramme ou un tableau de fréquences. Elles permettent d'estimer la tendance centrale (par ex., l'intervalle modal).
Étape 2 : Collecter les données
Recensement ou échantillonnage
Lorsque nous menons une enquête, nous devons décider auprès de qui collecter les données. Devons-nous interroger toute la population, ou seulement un groupe plus restreint ?
Définition Recensement ou Sondage
- Un recensement collecte des données auprès de chaque membre de la population. C'est précis mais peut être très lent et coûteux pour de grandes populations.
- Un sondage (ou échantillonnage) collecte des données auprès d'un groupe plus petit et gérable issu de la population, appelé un échantillon. C'est beaucoup plus rapide, mais l'échantillon doit être choisi avec soin pour être représentatif de l'ensemble de la population.
Exemple
Une enquête pose la question : « Quelle est la matière préférée des élèves de cette école ? »
Si tu interroges chaque élève de l'école, est-ce un recensement ou un sondage ?
Si tu interroges chaque élève de l'école, est-ce un recensement ou un sondage ?
C’est un recensement car tu collectes des données auprès de toute la population (tous les élèves de l'école).
Exemple
Une enquête pose la question : « Quelle est la matière préférée des élèves de cette école ? »
Si tu n'interroges que les élèves de ta classe de maths, est-ce un recensement ou un sondage ?
Si tu n'interroges que les élèves de ta classe de maths, est-ce un recensement ou un sondage ?
C’est un sondage car tu ne collectes des données que d'un petit échantillon (ta classe de maths) de la population totale (toute l'école).
Méthodes d'échantillonnage et erreurs potentielles
Lors de la réalisation d'un sondage, notre objectif est de sélectionner un échantillon qui soit représentatif de l'ensemble de la population. La méthode utilisée pour sélectionner cet échantillon est cruciale. Une méthode mal choisie peut conduire à un échantillon biaisé, où certaines parties de la population sont sur- ou sous-représentées, rendant les conclusions invalides.
Définition Échantillonnage probabiliste
Dans l'échantillonnage probabiliste, chaque membre de la population a une chance connue et non nulle d'être sélectionné. Ces méthodes sont conçues pour être non biaisées.
- Échantillonnage aléatoire simple : Chaque membre a une chance égale d'être sélectionné.
Exemple : Tirer 3 noms d'un chapeau contenant les noms des 30 élèves. - Échantillonnage systématique : Les membres sont sélectionnés à un intervalle régulier (\(k\)) à partir d'une liste ordonnée, en commençant par un point aléatoire entre 1 et \(k\).
Exemple : Interroger un client sur 20 entrant dans un magasin. - Échantillonnage stratifié : La population est divisée en sous-groupes (strates), et un échantillon aléatoire simple est prélevé dans chaque strate, souvent proportionnellement à sa taille.
Exemple : Une école avec 40\(\pourcent\) de garçons et 60\(\pourcent\) de filles prélève un échantillon aléatoire de 40 garçons et 60 filles.
Définition Échantillonnage non probabiliste
Dans l'échantillonnage non probabiliste, la sélection de l'échantillon n'est pas aléatoire et repose souvent sur le jugement ou la commodité du chercheur. Ces méthodes sont très sujettes aux biais.
- Échantillonnage de commodité : Sélectionner les membres les plus facilement accessibles de la population.
Exemple : Interroger uniquement ses propres amis sur un sujet concernant toute l'école. - Échantillonnage par quotas : Similaire à l'échantillonnage stratifié, mais les individus de chaque sous-groupe sont sélectionnés de manière non aléatoire (par ex., par commodité) jusqu'à ce qu'un quota soit atteint.
Exemple : Un chercheur a besoin de 30 participants masculins et 30 féminins et interroge simplement les 30 premiers de chaque sexe qu'il rencontre.
Définition Erreur totale d'un sondage
L'erreur totale d'un sondage est la différence entre une statistique d'échantillon et le vrai paramètre de la population. Elle se compose de deux types d'erreurs :
- Erreur d'échantillonnage : Variation naturelle et aléatoire due à l'observation d'un échantillon plutôt que de toute la population.
- Erreur hors échantillonnage : Erreurs systématiques découlant de la conception du sondage, telles que le biais de sélection ou l'erreur de mesure.
Définition Biais de sélection
Le biais de sélection se produit lorsque la méthode d'échantillonnage exclut systématiquement certaines parties de la population, conduisant à un échantillon non représentatif.
Exemple
Un exemple célèbre est le sondage du Literary Digest de 1936, qui a échantillonné à partir d'annuaires téléphoniques et de registres automobiles, excluant ainsi les électeurs les plus pauvres et prédisant à tort le résultat de l'élection.
Définition Erreur de mesure
L'erreur de mesure désigne les inexactitudes dans les données qui surviennent pendant le processus de collecte. Les causes courantes incluent :
- Questions mal formulées : Questions ambiguës, doubles ou orientées qui embrouillent ou influencent le répondant.
- Biais de réponse : Les répondants fournissent des réponses inexactes en raison de la désirabilité sociale (vouloir paraître sous un jour favorable) ou d'une mauvaise compréhension de la question.
Exemple
Un sondage demande aux élèves : « N'êtes-vous pas d'accord que les formidables mathématiques sont la matière la plus importante pour votre avenir ? »
Identifier la source de l'erreur.
Identifier la source de l'erreur.
Ceci est une source d'erreur de mesure. La question est orientée pour deux raisons :
- Elle utilise l'adjectif biaisé « formidables » pour décrire les mathématiques.
- Elle utilise l'expression « N'êtes-vous pas d'accord », qui pousse le répondant à répondre « Oui ».
Étape 3 : Analyser les données
Fréquences
Définition Effectif et fréquence
L’effectif est le nombre de fois que chaque catégorie apparaît dans nos données.
La fréquence (ou fréquence relative) est la proportion des données qui correspond à une catégorie. On peut l'écrire sous forme de fraction, de nombre décimal ou de pourcentage.$$ \text{Fréquence (en }\pourcent\text{)} = \frac{\text{Effectif}}{\text{Effectif total}} \times 100\pourcent $$
La fréquence (ou fréquence relative) est la proportion des données qui correspond à une catégorie. On peut l'écrire sous forme de fraction, de nombre décimal ou de pourcentage.$$ \text{Fréquence (en }\pourcent\text{)} = \frac{\text{Effectif}}{\text{Effectif total}} \times 100\pourcent $$
Exemple
On calcule les fréquences relatives pour notre enquête sur la « Matière préférée » auprès de 25 élèves :
| Matière | Effectif | Fréquence |
| Maths | 8 | \(8/25\times 100\pourcent = 32\pourcent\) |
| Sciences | 5 | \(5/25\times 100\pourcent = 20\pourcent\) |
| Sport | 7 | \(7/25\times 100\pourcent = 28\pourcent\) |
| Arts | 5 | \(5/25\times 100\pourcent = 20\pourcent\) |
| Total | 25 | 100\(\pourcent\) |
Tendance centrale
Définition Mesures de tendance centrale
Une mesure de tendance centrale est une valeur unique qui tente de décrire un ensemble de données en identifiant la position centrale au sein de cet ensemble. Les principales mesures sont la moyenne, la médiane et le mode.
Définition Mode
Le mode est la valeur ou la catégorie qui apparaît le plus souvent. Un ensemble de données peut avoir plus d'un mode.
Exemple
Les résultats de l'enquête « Matière préférée » sont présentés dans le tableau d'effectifs ci-dessous.
| Matière | Effectif |
| Maths | 8 |
| Sciences | 5 |
| Sport | 7 |
| Arts | 5 |
Le mode est la catégorie qui a l'effectif le plus élevé. En regardant le tableau, l'effectif le plus élevé est 8.
La matière correspondant à cet effectif est les Maths. Par conséquent, le mode est Maths. C'est la matière préférée.
La matière correspondant à cet effectif est les Maths. Par conséquent, le mode est Maths. C'est la matière préférée.
Définition Moyenne
La moyenne est la somme de toutes les valeurs numériques divisée par le nombre de valeurs.$$ \begin{aligned} \bar{x} &= \frac{\text{somme de toutes les valeurs}}{\text{nombre de valeurs}} \\
&= \frac{x_1 + x_2 + x_3 + \dots + x_n}{n}\end{aligned}$$
Exemple
Pour l'ensemble de données \(1, 4, 2, 3, 5, 4, 5, 4, 4\), quelle est la moyenne ?
$$ \text{Moyenne} = \frac{1 + 4 + 2 + 3 + 5 + 4 + 5 + 4 + 4}{9} = \frac{32}{9} \approx 3,56 $$
Définition Médiane
La médiane est la valeur centrale d'un ensemble de données qui a été ordonné du plus petit au plus grand.
- S’il y a un nombre impair de valeurs, la médiane est l'unique valeur du milieu.
- S’il y a un nombre pair de valeurs, il y a deux valeurs centrales et la médiane est la moyenne de ces deux valeurs.
Exemple
Pour l'ensemble de données \(1, 4, 2, 3, 5, 4, 5, 4, 4\), quelle est la médiane ?
- Ordonner les données : \(1, 2, 3, 4, 4, 4, 4, 5, 5\).
- Trouver la valeur centrale : Il y a 9 valeurs (un nombre impair), donc la valeur du milieu est la 5ième. $$1, 2, 3, 4, \underline{4}, 4, 4, 5, 5$$
Dispersion
Définition Mesures de dispersion
Une mesure de dispersion décrit à quel point les valeurs d'un ensemble de données sont variées ou « étalées ». Alors que la tendance centrale nous renseigne sur le centre, la dispersion nous renseigne sur la consistance des données. Les principales mesures sont l'étendue, l'écart interquartile (EIQ) et l'écart-type.
Exemple
Considérons les notes de deux élèves :
- Notes de l'élève A : 10, 50, 90
- Notes de l'élève B : 45, 50, 55
Définition Étendue
L'étendue est la différence entre la valeur maximale et la valeur minimale d’un ensemble de données. Elle donne une mesure rapide de la dispersion totale.$$ \text{Étendue} = \text{Valeur maximale} - \text{Valeur minimale} $$
Exemple
Détermine l’étendue pour les données : \(1, 19, 10, 2, 18, 10, 5, 15, 10\).
La valeur minimale est 1 et la valeur maximale est 19.
L’étendue est \(19 - 1 = 18\).
L’étendue est \(19 - 1 = 18\).
Définition Quartiles et Écart Interquartile
Les quartiles sont les valeurs qui divisent un ensemble de données ordonné en quatre parties égales.
L'écart interquartile (EIQ) est l'étendue des 50\(\pourcent\) du milieu des données. Il est moins affecté par les valeurs extrêmes que l'étendue.$$ \text{EIQ} = Q_3 - Q_1 $$
- Le premier quartile (Q1) est la médiane de la moitié inférieure des données.
- La médiane (Q2) est la médiane de l'ensemble des données.
- Le troisième quartile (Q3) est la médiane de la moitié supérieure des données.
L'écart interquartile (EIQ) est l'étendue des 50\(\pourcent\) du milieu des données. Il est moins affecté par les valeurs extrêmes que l'étendue.$$ \text{EIQ} = Q_3 - Q_1 $$
Exemple
Trouve les quartiles et l’écart interquartile pour les données : \(1, 19, 10, 2, 18, 10, 5, 15, 10\).
- Ordonner les données : \(1, 2, 5, 10, 10, 10, 15, 18, 19\).
- Trouver la médiane (Q2) : La valeur du milieu est la 5ième, donc \(Q_2 = 10\). $$ 1, 2, 5, 10, \underline{10}, 10, 15, 18, 19 $$
- Partager les données en deux moitiés (sans Q2) : Moitié inférieure : \(1, 2, 5, 10\) \(\quad\) Moitié supérieure : \(10, 15, 18, 19\).
- Trouver le premier quartile (Q1) : Trouver la médiane de la moitié inférieure. $$ 1, \underline{2, 5}, 10 \rightarrow Q_1 = \frac{2+5}{2} = 3,5 $$
- Trouver le troisième quartile (Q3) : Trouver la médiane de la moitié supérieure. $$ 10, \underline{15, 18}, 19 \rightarrow Q_3 = \frac{15+18}{2} = 16,5 $$
- Calculer l'EIQ : $$ \text{EIQ} = Q_3 - Q_1 = 16,5 - 3,5 = 13 $$
Étape 4 : Représenter les données
Visualiser les fréquences
Une fois les données organisées dans un tableau, nous pouvons créer des graphiques pour voir les tendances visuellement. Les diagrammes en bâtons sont excellents pour comparer les effectifs, tandis que les diagrammes circulaires sont idéaux pour montrer les proportions.
Définition Diagramme en bâtons
Un diagramme en bâtons utilise des barres rectangulaires où la hauteur de chaque barre représente son effectif. Il peut être utilisé pour des données qualitatives ou quantitatives.
- Pour les données qualitatives (catégorielles), chaque barre représente une catégorie distincte (ex : « Maths », « Sciences »). Les barres sont généralement dessinées avec des espaces entre elles pour montrer que les catégories sont séparées.
- Pour les données quantitatives (numériques), chaque barre représente un nombre spécifique (ex : une note de « 3 » ou « 4 frères et sœurs »). Les nombres sont placés dans l'ordre sur l'axe horizontal.
Exemple
Trace un diagramme en bâtons pour nos données de l'enquête « Matière préférée ».
| Matière | Effectif |
| Maths | 8 |
| Sciences | 5 |
| Sport | 7 |
| Arts | 5 |
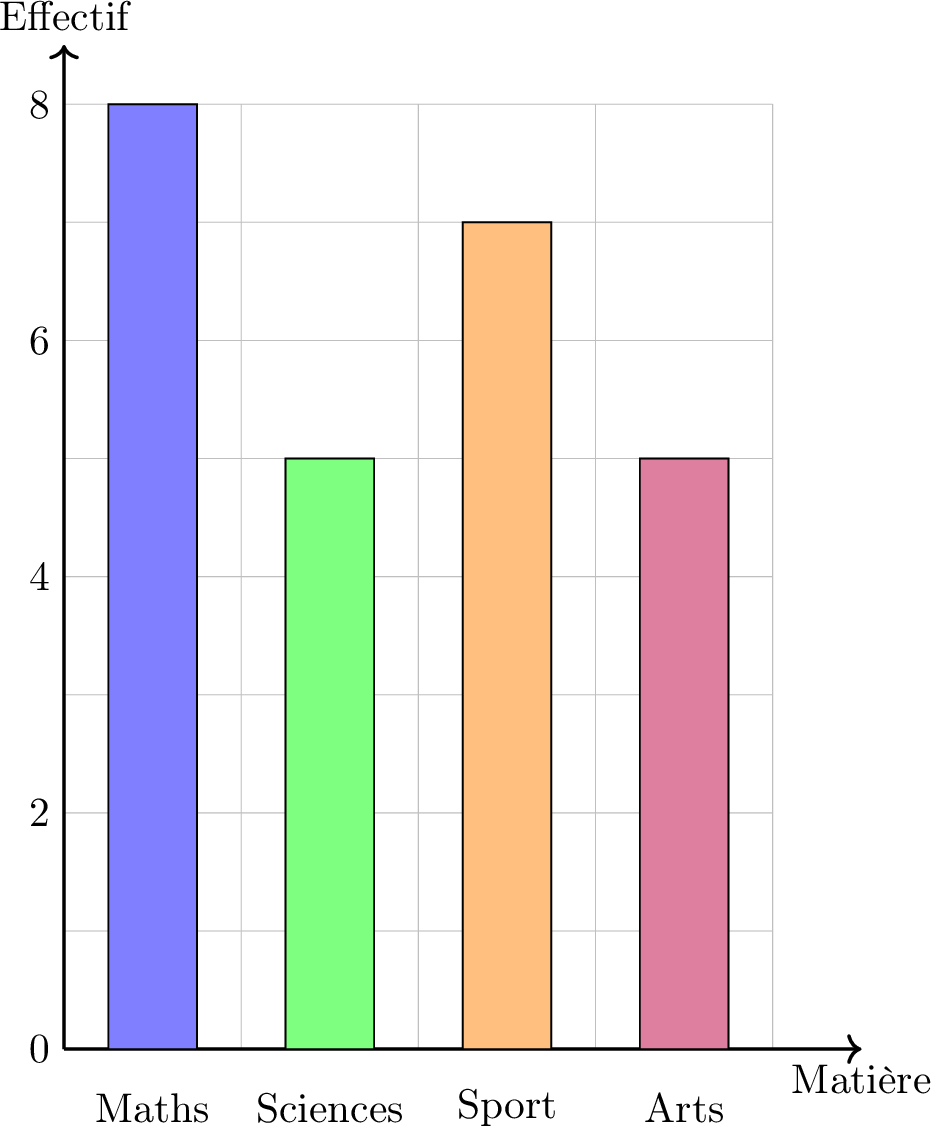
Définition Diagramme circulaire
Un diagramme circulaire montre la proportion de chaque catégorie sous forme de part d'un cercle. Si la fréquence relative d'une catégorie est écrite sous forme décimale (par exemple \(0{,}32\)), l'angle de sa part se calcule ainsi :$$ \text{Angle} = \text{fréquence relative} \times 360^\circ. $$
Exemple
Trace un diagramme circulaire pour nos données de l'enquête « Matière préférée » (Total = 25 élèves).
| Matière | Effectif | Fréquence |
| Maths | 8 | \(32\pourcent\) |
| Sciences | 5 | \(20\pourcent\) |
| Sport | 7 | \(28\pourcent\) |
| Arts | 5 | \(20\pourcent\) |
D'abord, calculons l'angle pour chaque part :
- Maths : \(0{,}32 \times 360^\circ \approx 115^\circ\)
- Sciences : \(0{,}20 \times 360^\circ = 72^\circ\)
- Sport : \(0{,}28 \times 360^\circ \approx 101^\circ\)
- Arts : \(0{,}20 \times 360^\circ = 72^\circ\)
Visualiser la tendance centrale et la dispersion
Bien que des mesures comme la moyenne et l'écart-type soient puissantes, elles ne donnent pas une image complète de la distribution des données. Un diagramme en boîte (ou boîte à moustaches) est un outil visuel qui résume un ensemble de données en montrant à la fois son centre et sa dispersion.
Définition Diagramme en boîte
Un diagramme en boîte affiche visuellement le résumé à cinq nombres au-dessus d'une droite numérique.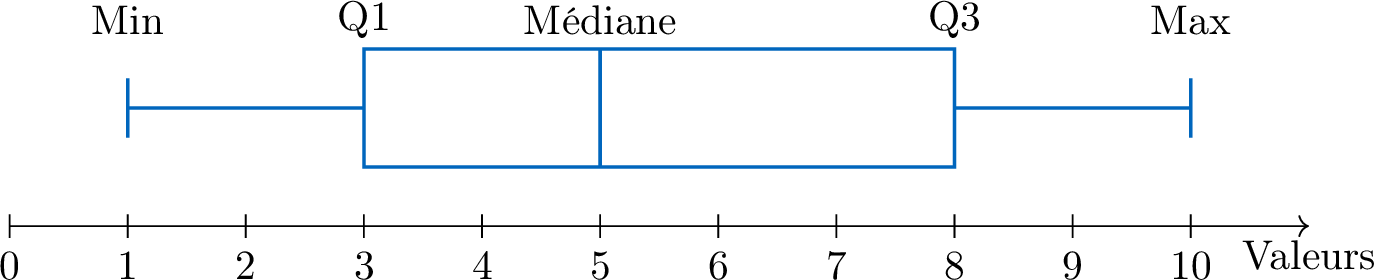
- Une boîte centrale est dessinée du premier quartile (Q1) au troisième quartile (Q3).
- Une ligne à l'intérieur de la boîte marque la médiane (Q2).
- Des moustaches (lignes) s'étendent de la boîte jusqu'aux valeurs minimale et maximale.
Méthode Construire un diagramme en boîte
- Ordonner les données de la plus petite à la plus grande.
- Trouver le résumé à cinq nombres : Calculer le minimum, Q1, la médiane, Q3 et le maximum.
- Dessiner une droite numérique qui couvre toute l'étendue de vos données.
- Dessiner la boîte et la médiane : Dessiner une boîte de Q1 à Q3 et une ligne verticale à l'intérieur à la position de la médiane.
- Dessiner les moustaches : Tracer des lignes de la boîte jusqu'aux valeurs minimale et maximale.
Exercice
Ce diagramme en boîte montre le nombre de minutes que des passagers ont passées dans une salle d'embarquement.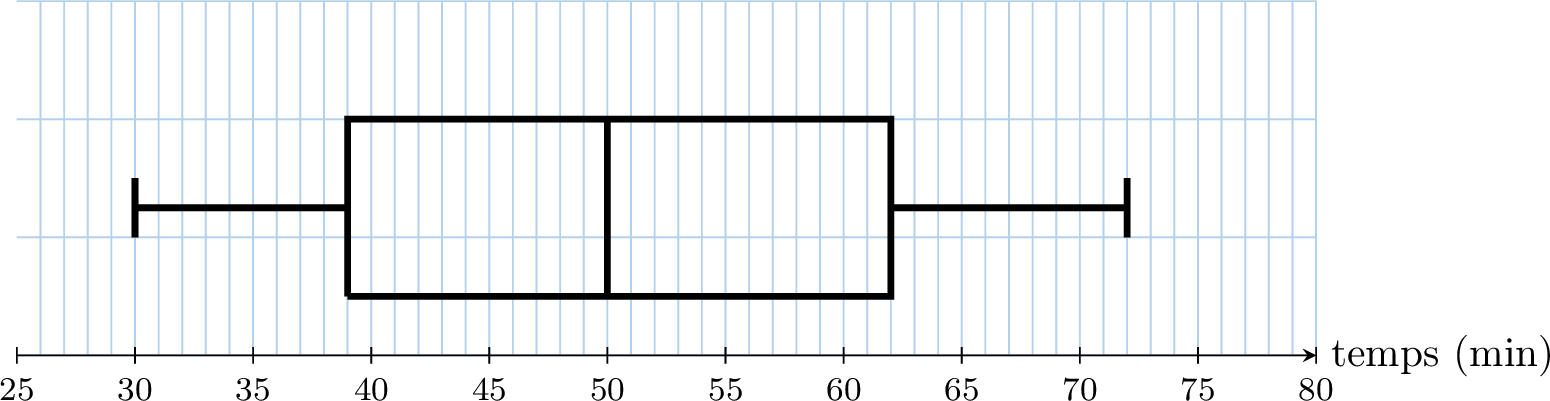
En lisant le résumé à cinq nombres sur le diagramme :
- Médiane (Q2) : La ligne à l'intérieur de la boîte est à 50 minutes.
- Étendue : Maximum - Minimum = \(72 - 30 = 42\) minutes.
- Écart interquartile (EIQ) : Q3 - Q1 = \(62 - 39 = 23\) minutes.
Étape 5 : Interpréter les données
Tirer des conclusions et évaluer des affirmations
Méthode Interpréter des résultats statistiques
Une interprétation rigoureuse des résultats statistiques comporte plusieurs étapes :
- Résumer les principaux résultats : Énoncer les résultats principaux de l'analyse, en se référant aux statistiques descriptives (moyenne, médiane, écart-type) et aux caractéristiques clés des représentations graphiques.
- Contextualiser les résultats : Relier les résultats à la question de recherche initiale. Que signifient ces chiffres dans le contexte du problème étudié ?
- Faire des inférences (le cas échéant) : Si les données proviennent d'un échantillon représentatif, faire une inférence prudente sur la population plus large. Il est crucial de reconnaître l'incertitude inhérente à la généralisation d'un échantillon à une population.
- Évaluer les limites : Évaluer de manière critique les limites de l'étude. Cela inclut l'examen des sources potentielles d'erreur (erreur d'échantillonnage, biais de sélection, erreur de mesure) et leur impact possible sur la validité et la généralisabilité des conclusions.
Méthode Évaluer de manière critique une affirmation statistique
Face à une affirmation statistique, une évaluation critique doit se concentrer sur deux domaines clés :
- Validité de la collecte de données : L'échantillon était-il représentatif de la population cible, ou un biais de sélection a-t-il pu influencer les résultats ? La taille de l'échantillon était-elle suffisante pour étayer la conclusion ? Les questions étaient-elles neutres et sans ambiguïté pour éviter les erreurs de mesure ?
- Portée de la conclusion : La conclusion surgénéralise-t-elle les résultats ? Une erreur courante est de confondre une tendance au sein d'un échantillon spécifique avec une vérité universelle. Une statistique descriptive (comme une moyenne) résume un groupe mais ne s'applique pas à chaque individu de ce groupe.
Exemple Evaluating a Claim
Affirmation : « Les filles sont meilleures en maths que les garçons. »
Preuve fournie : Une étude dans une classe a révélé que la note moyenne des filles était de 87\(\pourcent\), tandis que celle des garçons était de 75\(\pourcent\).
Évaluation critique : L'affirmation générale n'est pas justifiée par les preuves fournies.
Preuve fournie : Une étude dans une classe a révélé que la note moyenne des filles était de 87\(\pourcent\), tandis que celle des garçons était de 75\(\pourcent\).
Évaluation critique : L'affirmation générale n'est pas justifiée par les preuves fournies.
- Limites de l'échantillon (Généralisabilité) : L'échantillon ne comprend qu'une seule classe. Il n'est pas aléatoire et est trop petit pour être considéré comme représentatif de l'ensemble de la population des « filles » et des « garçons ». La conclusion ne peut pas être généralisée au-delà de ce groupe spécifique.
- Mauvaise interprétation des moyennes : La moyenne décrit la tendance centrale d'un groupe, pas la performance des individus. Même avec une moyenne plus élevée, il est très probable que certains garçons de la classe aient obtenu de meilleures notes que certaines filles. L'affirmation « les filles sont meilleures » est une surgénéralisation qui implique à tort que cela est vrai pour chaque individu.