Sommes et théorèmes limites de variables aléatoires
De nombreuses situations concrètes mettent en jeu des variables aléatoires définies comme la somme ou la moyenne d'autres variables aléatoires. Par exemple, l'estimation de la moyenne d'une population à partir de la moyenne d'un échantillon repose sur le comportement de ces sommes et de ces moyennes. Les théorèmes limites fournissent la justification mathématique de ce type d'estimations.
Les théorèmes limites décrivent le comportement des sommes (ou des moyennes) de variables aléatoires lorsque le nombre de termes augmente. Dans ce chapitre, nous nous concentrerons sur deux outils essentiels :
Les théorèmes limites décrivent le comportement des sommes (ou des moyennes) de variables aléatoires lorsque le nombre de termes augmente. Dans ce chapitre, nous nous concentrerons sur deux outils essentiels :
- Les inégalités de concentration : elles permettent de majorer la probabilité qu'une variable s'écarte fortement de son espérance.
- La loi des grands nombres (LGN) : elle explique pourquoi les moyennes se stabilisent : lorsque l'on répète une expérience un grand nombre de fois, la moyenne des résultats se rapproche de plus en plus de l'espérance théorique.
Modélisation par combinaisons linéaires
En théorie des probabilités, on analyse souvent des situations qui résultent de la répétition d'une même expérience ou de la combinaison de plusieurs phénomènes aléatoires. Pour les modéliser, on introduit de nouvelles variables aléatoires comme des sommes, des moyennes, ou plus généralement des combinaisons linéaires de variables plus simples.
Par exemple, le profit total sur une semaine est la somme des profits quotidiens.
Par exemple, le profit total sur une semaine est la somme des profits quotidiens.
Définition Combinaison linéaire de variables aléatoires
Une combinaison linéaire de variables aléatoires \(X_1, X_2, \ldots, X_n\) est une nouvelle variable aléatoire \(Y\) définie par :$$ Y = a_1 X_1 + a_2 X_2 + \ldots + a_n X_n, $$où \(a_1, a_2, \ldots, a_n\) sont des constantes réelles.
Définition Somme et moyenne de variables aléatoires
Étant données \(n\) variables aléatoires \(X_1, X_2, \dots, X_n\) :
- La somme est notée \(S_n = X_1 + X_2 + \ldots + X_n\).
- La moyenne d'échantillon (ou moyenne empirique) est notée \(\overline{X}_n = \dfrac{X_1 + X_2 + \ldots + X_n}{n}\).
Exemple
On lance deux dés équilibrés à six faces. On note \(X_1\) le résultat du premier dé  et \(X_2\) le résultat du second dé
et \(X_2\) le résultat du second dé .
.
- Le score total est \(S_2 = X_1 + X_2\).
- La moyenne est \(\overline{X}_2 = \dfrac{X_1 + X_2}{2}\).
Espérance et variance
Lorsqu'une variable aléatoire est définie comme la somme ou la moyenne d'autres variables, déterminer sa loi de probabilité peut être très laborieux (par exemple, établir la loi de la somme de \(100\) dés).
Heureusement, grâce à la linéarité de l'espérance et à l'additivité de la variance (en cas d'indépendance), on peut calculer l'espérance et la variance de ces combinaisons directement à partir des variables individuelles, sans établir la loi complète du résultat.
Heureusement, grâce à la linéarité de l'espérance et à l'additivité de la variance (en cas d'indépendance), on peut calculer l'espérance et la variance de ces combinaisons directement à partir des variables individuelles, sans établir la loi complète du résultat.
Proposition Propriétés de l'espérance et de la variance
Pour des variables aléatoires \(X, Y\) et des réels \(a, b\) :
- L'espérance est linéaire : pour tous \(a,b\in\mathbb{R}\), $$ E(aX + bY) = aE(X) + bE(Y). $$
- La variance s'additionne pour des variables indépendantes : si \(X\) et \(Y\) sont indépendantes, alors $$ V(aX + bY) = a^2V(X) + b^2V(Y). $$
Exemple
Soient \(X_1\) et \(X_2\) les résultats du lancer de deux dés équilibrés. Pour un dé, on sait que\(E(X_1)=3{,}5\) et \(V(X_1)=\dfrac{35}{12}\approx 2{,}92\).
- L'espérance de la somme est \(E(X_1+X_2)=E(X_1)+E(X_2)=3{,}5+3{,}5=7\).
- Les dés étant indépendants, la variance de la somme est \(V(X_1+X_2)=V(X_1)+V(X_2)=\dfrac{70}{12}\approx 5{,}83\).
Proposition Espérance des sommes et des moyennes
Si \(E(\overline{X}_i) = \mu\), pour tout \(i\), alors :$$ E(S_n) = n\mu \qquad\text{et}\qquad E(\overline{X}_n) = \mu. $$
Par linéarité de l'espérance :$$ \begin{aligned}E(S_n) &= E(X_1 + \cdots + X_n) = E(X_1) + \cdots + E(X_n) = n\mu,\\
E(\overline{X}_n) &= E\!\left(\frac{S_n}{n}\right) = \frac{1}{n}E(S_n) = \frac{n\mu}{n} = \mu.\end{aligned} $$
Exemple
Si l'on lance \(n=10\) dés, l'espérance du score moyen par dé reste \(3{,}5\) :$$ E(\overline{X}_{10}) = E(X_1) = 3{,}5. $$Le score total attendu est \(E(S_{10}) = 10 \times 3{,}5 = 35\).
Proposition Variance des sommes et des moyennes
Si \(X_1, X_2, \dots, X_n\) sont indépendantes et identiquement distribuées, de variance \(\sigma^2\) (et d'écart-type \(\sigma\)), alors :
- Pour la somme : $$ V(S_n) = n\sigma^2 \quad \text{et} \quad \sigma(S_n) = \sigma\sqrt{n}. $$
- Pour la moyenne : $$ V(\overline{X}_n) = \frac{\sigma^2}{n} \quad \text{et} \quad \sigma(\overline{X}_n) = \frac{\sigma}{\sqrt{n}}. $$
Par additivité de la variance pour des variables indépendantes et la propriété \(V(aX)=a^2V(X)\) :$$ \begin{aligned}V(S_n) &= V(X_1 + \cdots + X_n) = V(X_1) + \cdots + V(X_n) = n\sigma^2,\\
\sigma(S_n) &= \sqrt{V(S_n)} = \sqrt{n\sigma^2} = \sigma\sqrt{n},\\
V(\overline{X}_n) &= V\!\left(\frac{1}{n}S_n\right) = \frac{1}{n^2}V(S_n) = \frac{n\sigma^2}{n^2} = \frac{\sigma^2}{n},\\
\sigma(\overline{X}_n) &= \sqrt{V(\overline{X}_n)} = \sqrt{\frac{\sigma^2}{n}} = \frac{\sigma}{\sqrt{n}}.\end{aligned} $$
Exemple
On considère le lancer de \(n=100\) dés. La variance de la moyenne \(\overline{X}_{100}\) est :$$ V(\overline{X}_{100}) = \frac{V(X_1)}{100} = \frac{2{,}92}{100} = 0{,}0292. $$L'écart-type vaut \(\sigma(\overline{X}_{100}) = \dfrac{\sigma(X_1)}{\sqrt{100}} = \dfrac{1{,}71}{10} = 0{,}171\).
Comparée à celle d'un seul dé (\(\sigma \approx 1{,}71\)), la moyenne de \(100\) dés est beaucoup moins dispersée et donc beaucoup plus stable (elle se concentre autour de l'espérance).
Comparée à celle d'un seul dé (\(\sigma \approx 1{,}71\)), la moyenne de \(100\) dés est beaucoup moins dispersée et donc beaucoup plus stable (elle se concentre autour de l'espérance).
Lois de concentration
Lorsque nous connaissons l'espérance \(\mu\) et la variance \(V\) d'une variable aléatoire, nous voulons souvent savoir quelle est la probabilité que la variable prenne une valeur très éloignée de sa moyenne.
Les inégalités de concentration fournissent un moyen mathématique de majorer cette probabilité. Contrairement aux lois de probabilité spécifiques, ces inégalités fonctionnent pour n'importe quelle variable aléatoire, offrant une limite supérieure sur la probabilité d'un écart. Ces inégalités sont des outils fondamentaux que nous utiliserons pour démontrer rigoureusement la loi des grands nombres.
Les inégalités de concentration fournissent un moyen mathématique de majorer cette probabilité. Contrairement aux lois de probabilité spécifiques, ces inégalités fonctionnent pour n'importe quelle variable aléatoire, offrant une limite supérieure sur la probabilité d'un écart. Ces inégalités sont des outils fondamentaux que nous utiliserons pour démontrer rigoureusement la loi des grands nombres.
Theorem Inégalité de Bienaymé-Tchebychev
Soit \(X\) une variable aléatoire d'espérance \(\mu\) et de variance \(V(X)\). Pour tout réel \(\delta>0\) :$$ P\bigl(|X-\mu|\ge \delta\bigr)\le \frac{V(X)}{\delta^2}. $$Cette inégalité majore la probabilité que \(X\) s'écarte de son espérance d'au moins \(\delta\).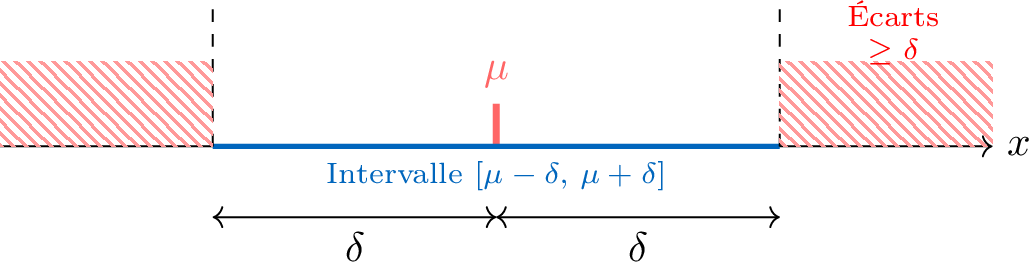
Exemple
Une usine produit des sacs de sucre de poids moyen \(\mu=1000\,\text{g}\) et de variance \(V(X)=25\). On cherche à majorer la probabilité que le poids d'un sac s'écarte de la moyenne de \(10\,\text{g}\) ou plus.Ici \(\delta=10\). D'après l'inégalité :$$ P(|X-1000|\ge 10)\le \frac{25}{10^2}=0{,}25. $$Il y a au plus \(25\,\pourcent\) de chances qu'un sac soit en dehors de l'intervalle \([990,\,1010]\).
Proposition Inégalité de concentration
Soit \(\overline{X}_n\) la moyenne d'échantillon de \(n\) variables indépendantes et identiquement distribuées, d'espérance \(\mu\) et de variance \(V\). Pour tout \(\delta>0\) :$$ P\bigl(|\overline{X}_n-\mu|\ge \delta\bigr)\le \frac{V}{n\delta^2}. $$Ce résultat montre que, lorsque \(n\) augmente, la probabilité que la moyenne soit éloignée de \(\mu\) tend vers \(0\).
Exemple
On lance une pièce équilibrée \(n=1000\) fois. Soit \(\overline{X}_n\) la proportion observée de face. On a alors \(\mu=0{,}5\) et \(V=0{,}25\). Quelle est la probabilité que la proportion s'écarte de \(0{,}5\) de plus de \(0{,}05\) ?En utilisant l'inégalité de concentration avec \(\delta=0{,}05\) :$$ P(|\overline{X}_{1000}-0{,}5|\ge 0{,}05)\le \frac{0{,}25}{1000\times 0{,}0025}=0{,}1. $$Il y a au plus \(10\,\pourcent\) de chances que la proportion soit en dehors de l'intervalle \([0{,}45;\,0{,}55]\).
Loi des grands nombres
Depuis l'enfance, nous utilisons intuitivement les fréquences expérimentales pour estimer des probabilités — par exemple, en lançant une pièce de monnaie de nombreuses fois pour vérifier si elle est équilibrée. La loi des grands nombres apporte une justification mathématique rigoureuse à cette intuition : à mesure que le nombre d'essais indépendants augmente, la moyenne d'échantillon devient une estimation de plus en plus fiable de l'espérance théorique.
Theorem Loi des grands nombres
Soient \(X_1, X_2, \dots, X_n\) des variables aléatoires indépendantes et identiquement distribuées, d'espérance \(\mu\) et de variance \(V\). Soit \(\overline{X}_n\) leur moyenne d'échantillon. Pour tout \(\delta>0\) :$$ \lim_{n\to\infty} P(|\overline{X}_n-\mu|\ge \delta)=0. $$Autrement dit, pour tout \(\delta\) fixé, la probabilité que la moyenne d'échantillon s'écarte de \(\mu\) d'au moins \(\delta\) tend vers \(0\) lorsque \(n\to\infty\).
D'après l'inégalité de concentration :$$ P(|\overline{X}_n-\mu|\ge \delta)\le \frac{V}{n\delta^2}. $$Comme \(V\) et \(\delta\) sont fixés, on a$$ \lim_{n\to\infty}\frac{V}{n\delta^2}=0. $$La probabilité étant positive et majorée par une suite qui tend vers \(0\), on conclut (théorème des gendarmes) que$$ \lim_{n\to\infty} P(|\overline{X}_n-\mu|\ge \delta)=0. $$
Exemple
Considérons le lancer d'une pièce équilibrée (\(p=0{,}5\)). Pour \(n=100\), l'inégalité de concentration donne :$$ P(|\overline{X}_{100}-0{,}5|\ge 0{,}1)\le \frac{0{,}25}{100\times 0{,}1^2}=0{,}25. $$Mais pour \(n=1\,000\,000\) :$$ P(|\overline{X}_{1\,000\,000}-0{,}5|\ge 0{,}1)\le \frac{0{,}25}{1\,000\,000\times 0{,}1^2}=0{,}000025. $$La moyenne devient extrêmement stable autour de la valeur théorique à mesure que \(n\) augmente.