Variables bivariées
En statistique univariée, nous analysons une seule variable à la fois. La statistique bivariée étend cette analyse pour explorer la relation entre deux variables. En examinant des paires de données, nous pouvons rechercher des motifs, déterminer la nature et la force de leur relation, et utiliser cette relation pour faire des prédictions. Ce chapitre se concentre sur la relation entre deux variables quantitatives.
Variables bivariées
Définition Données bivariées
Les données bivariées se composent de paires de valeurs pour deux variables quantitatives, enregistrées pour chaque individu d'un ensemble de données. Nous notons généralement ces variables \((x, y)\), où :
- \(x\) est la variable indépendante (ou variable explicative).
- \(y\) est la variable dépendante (ou variable de réponse).
Exemple
Un enseignant enregistre les heures d'étude de chaque élève (\(x\)) et leur note à l'examen final (\(y\)).
| Heures d'étude (\(x\)) | 5 | 10 | 8 | 15 |
| Note à l'examen (\(y\)) | 50 | 85 | 75 | 95 |
Nuages de points
Définition Nuage de points
Un nuage de points est un graphique qui affiche des données bivariées sous forme d'un ensemble de points dans le plan cartésien. La variable indépendante (explicative) est placée sur l'axe horizontal (axe des \(x\)), et la variable dépendante (réponse) est placée sur l'axe vertical (axe des \(y\)).
Un nuage de points est l'outil principal pour identifier visuellement une relation potentielle, ou corrélation, entre deux variables quantitatives.
Méthode Construire un nuage de points
- Identifier les variables : Déterminer quelle variable est indépendante (\(x\)) et quelle est dépendante (\(y\)).
- Préparer les axes : Dessiner et légender l'axe horizontal pour la variable \(x\) et l'axe vertical pour la variable \(y\). Choisir des échelles appropriées pour les deux axes qui couvrent l'étendue des données.
- Placer les points : Pour chaque paire de valeurs (\(x, y\)) de votre ensemble de données, placer un unique point sur le graphique aux coordonnées correspondantes.
Exemple
Un enseignant a enregistré le nombre d’heures d’étude des élèves et leurs notes aux examens. Les données sont présentées ci-dessous :
| Heures d’étude (\(x\)) | 5 | 10 | 8 | 15 |
| Note à l’examen (\(y\)) | 50 | 85 | 75 | 95 |
- Variables : « Heures d’étude » est la variable indépendante (\(x\)) et « Note à l’examen » est la variable dépendante (\(y\)).
- Axes : L'axe des x sera légendé « Heures d’étude » et l'axe des y « Note à l’examen ». Les échelles doivent couvrir les plages de données.
- Placer les points : Nous plaçons les quatre paires de coordonnées : (5, 50), (10, 85), (8, 75) et (15, 95).
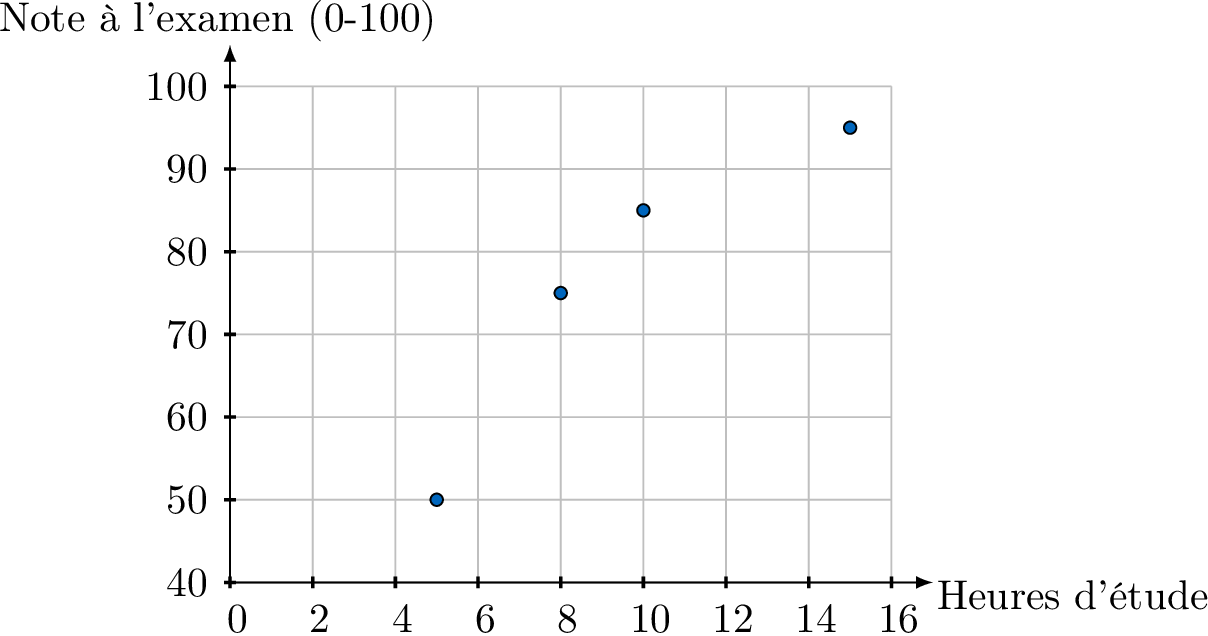
Corrélation
Définition Corrélation
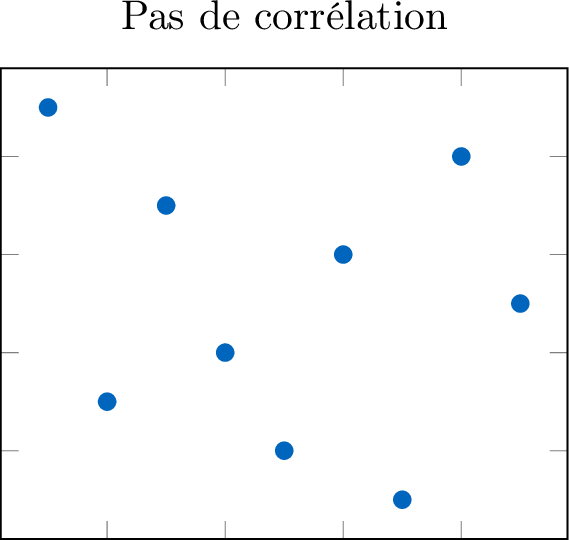
La corrélation décrit la nature de la relation entre deux variables quantitatives.
Définition Direction : Positive ou Négative
La direction décrit la tendance générale des données.
- Positive : Lorsque la variable indépendante (\(x\)) augmente, la variable dépendante (\(y\)) a tendance à augmenter. Les points suivent une tendance à la hausse.
- Négative : Lorsque la variable indépendante (\(x\)) augmente, la variable dépendante (\(y\)) a tendance à diminuer. Les points suivent une tendance à la baisse.
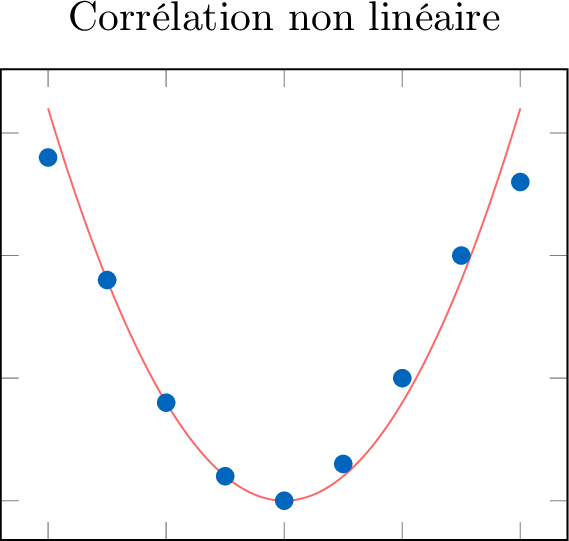
Définition Forme : Linéaire ou non linéaire
La forme de la relation est linéaire si les points de données semblent suivre un motif de ligne droite. S'ils suivent une autre courbe qu'une droite, la forme est non linéaire.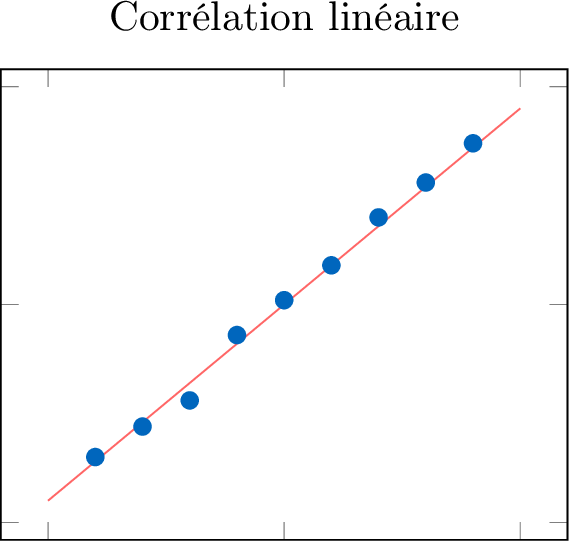
Définition Force
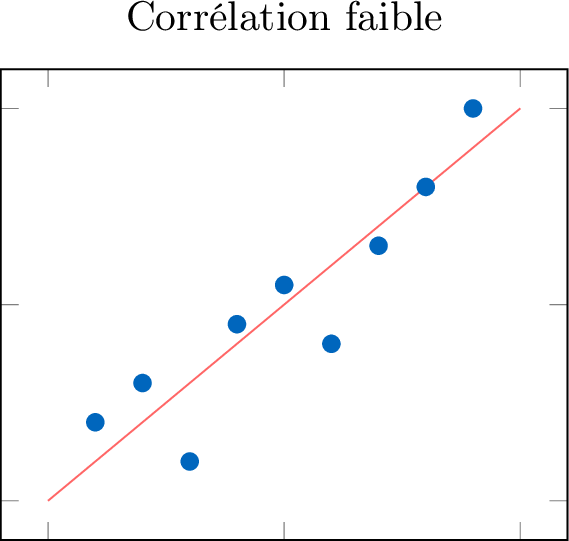
La force d'une corrélation décrit à quel point les points de données adhèrent à la forme identifiée.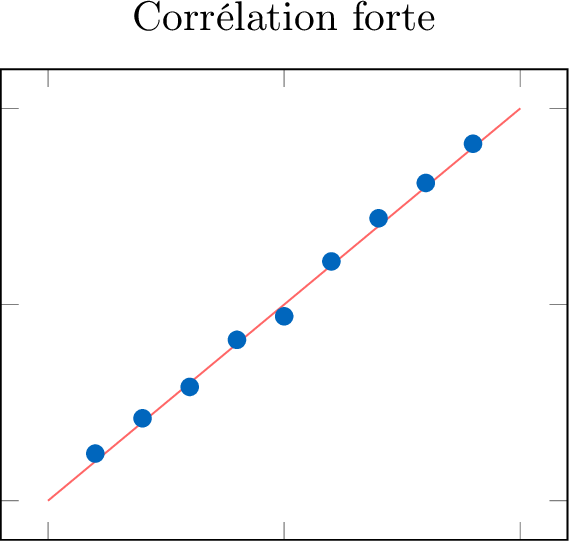
Définition Données aberrantes
Une donnée aberrante est un point de données qui s'écarte de manière significative du motif principal des données.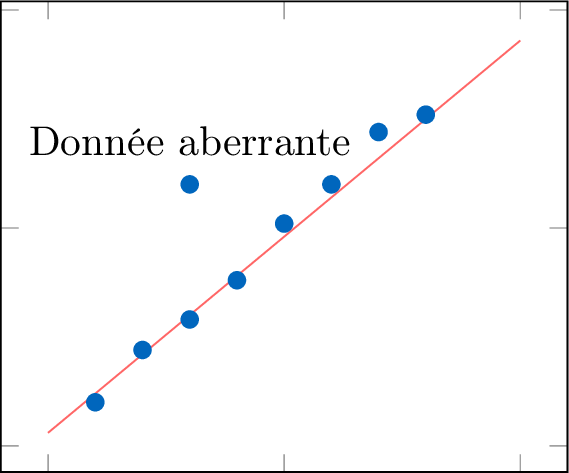
Méthode Décrire une corrélation
Lorsqu'on demande de décrire la relation montrée dans un nuage de points, on doit toujours commenter les quatre caractéristiques dans une déclaration concise.
- Direction : Est-elle positive ou négative ?
- Forme : Est-elle linéaire ou non linéaire ?
- Force : Est-elle forte, modérée ou faible ?
- Données aberrantes : Y a-t-il des données aberrantes notables ?
Exemple
Décrire la corrélation entre les heures d'étude et les notes à l'examen montrée dans ce nuage de points.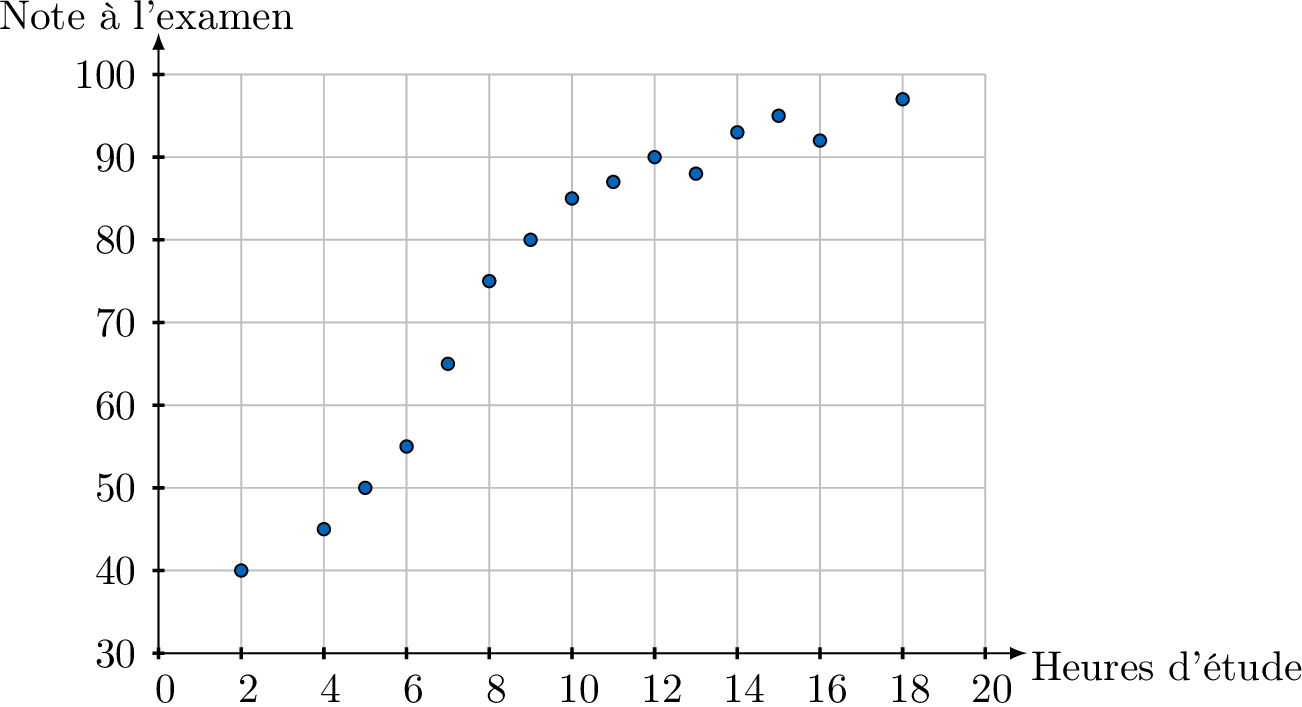
Il semble y avoir une corrélation linéaire positive et forte entre les heures d'étude et les notes à l'examen. À mesure que le nombre d'heures d'étude augmente, la note à l'examen a tendance à augmenter selon un motif linéaire. Il n'y a pas de données aberrantes évidentes.
Corrélation et Causalité
La corrélation n'implique pas la causalité
L'observation d'une relation statistique (corrélation) entre deux variables, \(x\) et \(y\), n'est pas une preuve suffisante pour conclure qu'un changement de \(x\) provoque un changement de \(y\).
Définition Causalité
La causalité n'existe que s'il est démontré qu'un changement de la variable indépendante provoque directement un changement de la variable dépendante. La preuve de la causalité nécessite une expérience contrôlée soigneusement conçue, et non de simples données d'observation.
Définition Variable de confusion
Souvent, une corrélation entre deux variables (\(x\) et \(y\)) est en réalité causée par un troisième facteur non observé, appelé variable de confusion (\(z\)). Cette variable influence à la fois \(x\) et \(y\), créant entre eux une relation apparente mais trompeuse.
Exemple
Les données montrent une forte corrélation positive entre les ventes de glaces et le nombre de coups de soleil.
Cela signifie-t-il que manger des glaces provoque des coups de soleil ? Sinon, identifier les relations et la probable variable de confusion.
Cela signifie-t-il que manger des glaces provoque des coups de soleil ? Sinon, identifier les relations et la probable variable de confusion.
Non, manger des glaces ne provoque pas de coups de soleil.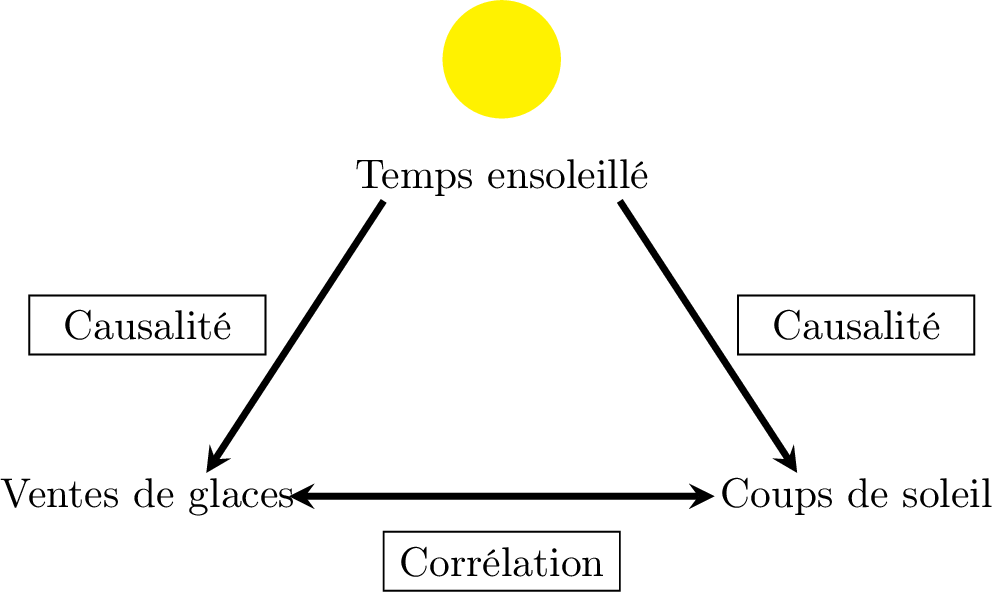
- La relation entre les ventes de glaces et les cas de coups de soleil est une corrélation, et non une causalité.
- La variable de confusion probable est le temps ensoleillé. Les journées chaudes et ensoleillées provoquent une augmentation des ventes de glaces et provoquent également une augmentation du nombre de personnes qui prennent des coups de soleil.
Mesurer la corrélation
Bien que les nuages de points nous permettent de décrire visuellement une corrélation, cette évaluation est subjective. Pour fournir une mesure précise et objective de la force et de la direction d'une relation linéaire, nous utilisons des coefficients numériques.
Définition Coefficient de corrélation de Pearson (r)
Le coefficient de corrélation de Pearson, noté \(r\), est une mesure de la corrélation linéaire entre deux ensembles de données. Il est défini comme le rapport de la covariance au produit des écarts-types :$$ r = \frac{\text{cov}(x,y)}{\sigma_x \sigma_y} $$où \(\text{cov}(x,y)\) est la covariance et \(\sigma_x\), \(\sigma_y\) sont les écarts-types de \(x\) et \(y\).
Méthode Utiliser la technologie pour calculer
En pratique, le calcul de \(r\) à la main est fastidieux pour les grands ensembles de données. On utilise une calculatrice graphique ou un logiciel statistique.
- Entrer les données bivariées dans deux listes (par ex. Liste 1 pour \(x\) et Liste 2 pour \(y\)).
- Choisir le calcul de régression linéaire (souvent noté \texttt{RegLin(ax+b)} ou similaire).
- Lire la valeur de \(r\) affichée à l'écran. (Note : Sur certaines calculatrices, il faut activer les « Diagnostics » pour voir \(r\)).
Proposition Propriétés du coefficient de corrélation de Pearson (r)
Le coefficient de corrélation de Pearson (\(r\)) est une valeur dans l'intervalle \([-1, 1]\) qui quantifie la direction et la force d'une relation linéaire entre deux variables quantitatives.
- Le signe de \(r\) indique la direction (positive ou négative).
- La valeur absolue de \(r\) indique la force. Une valeur de \(|r|\) proche de 1 implique une forte corrélation linéaire, tandis qu'une valeur proche de 0 implique une corrélation linéaire faible ou nulle.
| Valeur de \(|r|\) | Force de la corrélation |
| \(|r| = 1\) | Parfaite |
| \(0,9 \le |r| < 1\) | Très forte |
| \(0,7 \le |r| < 0,9\) | Forte |
| \(0,5 \le |r| < 0,7\) | Modérée |
| \(0,3 \le |r| < 0,5\) | Faible |
| \(0 \le |r| < 0,3\) | Très faible ou nulle |
Régression linéaire
Lorsqu'un nuage de points indique une corrélation linéaire entre deux variables, nous pouvons modéliser cette relation par une droite. Cette droite, appelée droite de régression, peut être utilisée pour faire des prédictions. La fiabilité de ce modèle est souvent évaluée à l'aide du coefficient de détermination (\(r^2\)). Une valeur élevée de \(r^2\) indique qu'une grande partie de la variance de la variable dépendante est expliquée par la variable indépendante, ce qui suggère que le modèle linéaire est bien ajusté aux données.
Définition Droite de régression des moindres carrés
La droite de régression des moindres carrés, écrite sous la forme \(y = ax + b\), est l'unique droite du meilleur ajustement qui modélise la relation linéaire entre \(x\) et \(y\). Elle est calculée en minimisant la somme des carrés des résidus.
Un résidu est la distance verticale entre un point de donnée observé \((x_i, y_i)\) et le point prédit sur la droite de régression \((x_i, \hat{y}_i)\).$$ \text{Résidu} = y_{\text{observé}} - y_{\text{prédit}} = y_i - \hat{y}_i $$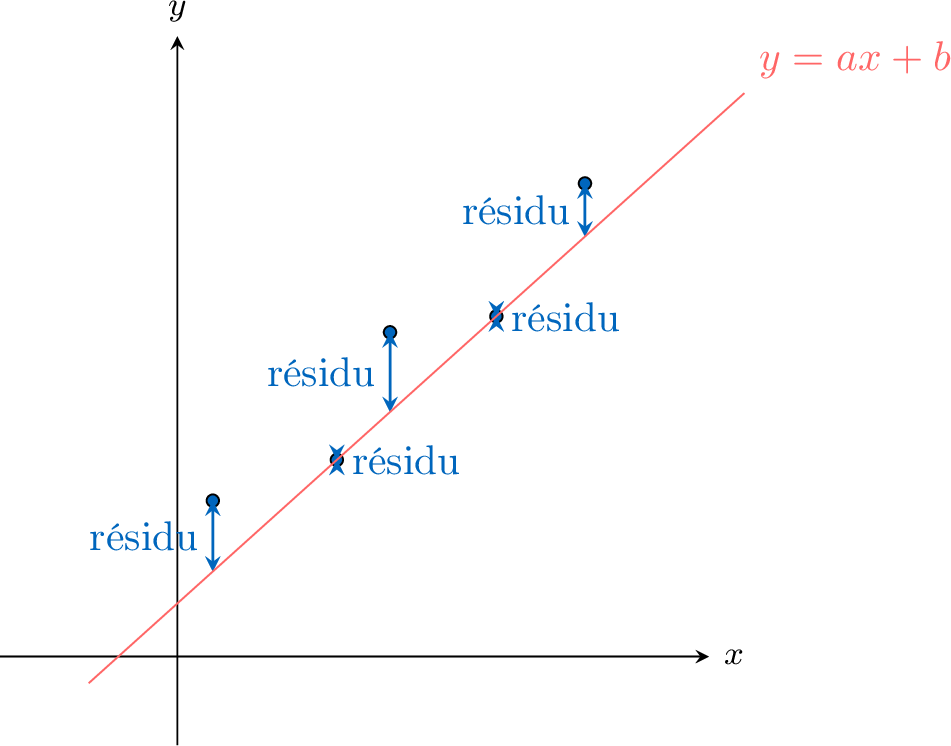
Un résidu est la distance verticale entre un point de donnée observé \((x_i, y_i)\) et le point prédit sur la droite de régression \((x_i, \hat{y}_i)\).$$ \text{Résidu} = y_{\text{observé}} - y_{\text{prédit}} = y_i - \hat{y}_i $$
Méthode Calculer les coefficients de régression
En pratique, en particulier pour les grands ensembles de données, l'équation de la droite de régression est déterminée à l'aide des fonctions statistiques d'une calculatrice (GDC) ou d'un logiciel. Cependant, il est possible de calculer les coefficients manuellement à l'aide de statistiques récapitulatives.
Une propriété fondamentale de la droite de régression des moindres carrés est sa relation avec les moyennes arithmétiques des ensembles de données. Cette propriété est fréquemment utilisée pour trouver des variables manquantes sans avoir besoin de l'ensemble complet des données.
Proposition Point moyen
La droite de régression des moindres carrés (\(y = ax + b\)) passe par le point défini par la moyenne des valeurs \(x\) et la moyenne des valeurs \(y\) : \((\bar{x}, \bar{y})\).$$ \bar{y} = a\bar{x} + b $$
Exemple
Le temps moyen d'étude hebdomadaire et le score final au test de mathématiques pour une sélection d'étudiants sont indiqués ci-dessous :
| Temps d'étude (\(x\) heures) | 2 | 5 | 1 | 7 | 4 | 9 | 6 | 3 |
| Score (\(y\) points) | 45 | 65 | 30 | 85 | 60 | 95 | 70 | 55 |
- Construis un nuage de points pour illustrer les données.
- Trouve l'équation de la droite de régression de \(y\) en \(x\). Donne et interprète son gradient (coefficient directeur) dans le contexte du problème.
- Estime le score au test pour un étudiant qui étudie 8 heures par semaine.
- Estime le temps d'étude hebdomadaire pour un étudiant qui obtient un score de 40 points.
- Nuage de points :
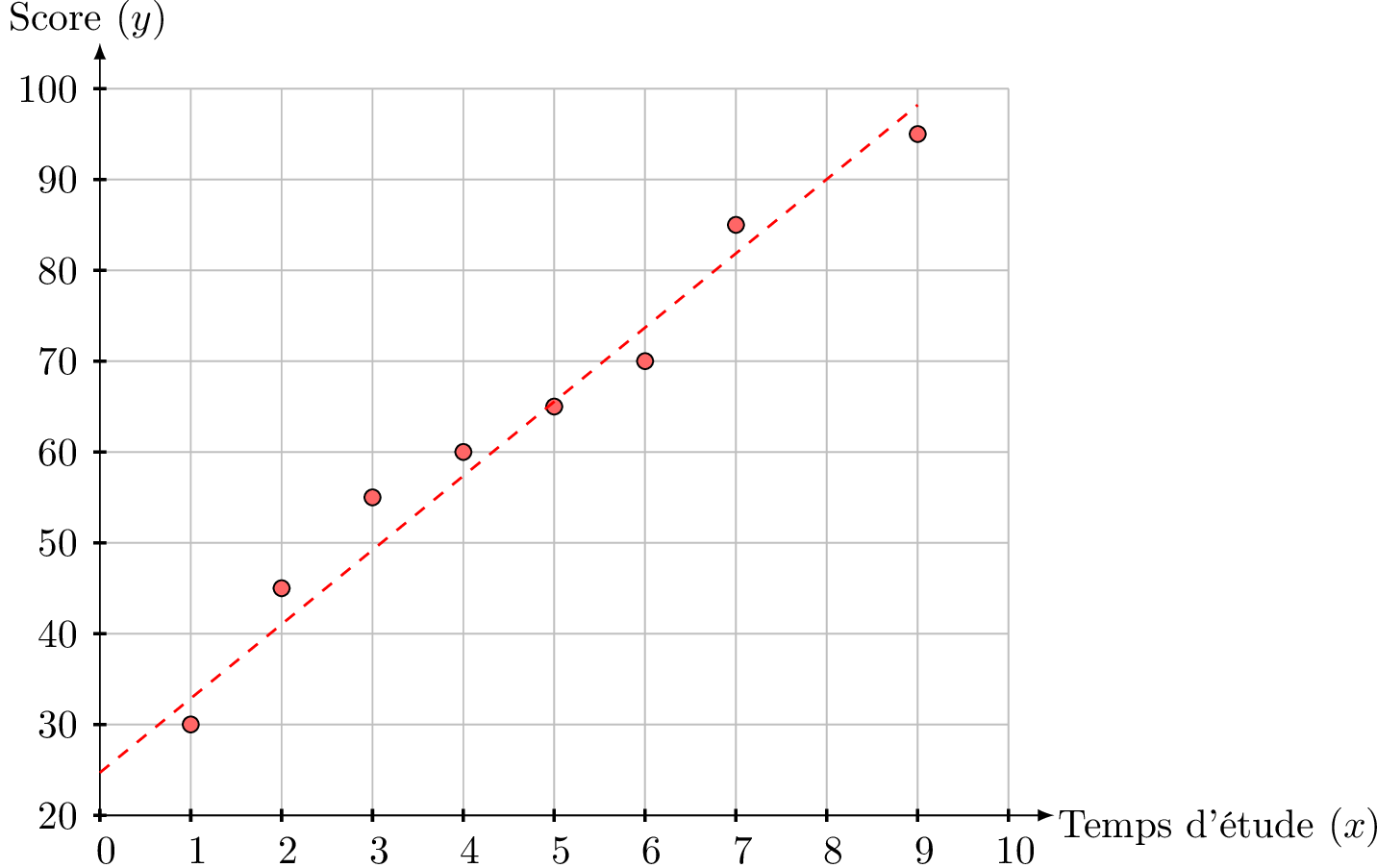
- Droite de régression :
À l'aide d'une calculatrice, l'équation est approximativement : $$y = 8{,}17x + 24{,}7$$ Interprétation :
Le gradient (coefficient directeur) est de \(8{,}17\). Cela signifie que pour chaque heure supplémentaire passée à étudier par semaine, le score au test augmente d'environ 8,17 points en moyenne. - Estimation (Score pour 8 heures) :
On remplace \(x = 8\) dans l'équation : $$y = 8{,}17(8) + 24{,}7 = 90{,}06$$ Le score estimé est d'environ 90 points. - Estimation (Temps pour 40 points) :
On remplace \(y = 40\) dans l'équation : $$40 = 8{,}17x + 24{,}7$$ $$15{,}3 = 8{,}17x$$ $$x \approx 1{,}87$$ Le temps d'étude estimé est d'environ 1,9 heures.