Bivariate Statistics
In univariate statistics, we analyze a single variable at a time. Bivariate statistics extends this analysis to explore the relationship between two variables. By examining pairs of data, we can investigate patterns, determine the nature and strength of their relationship, and use this relationship to make pictions. This chapter focuses on the relationship between two quantitative variables.
Bivariate Variables
Definition Bivariate Data
Bivariate data consists of pairs of values for two quantitative variables, recorded for each individual in a dataset. We typically denote these variables as \((x, y)\), where:
- \(x\) is the independent (or explanatory) variable.
- \(y\) is the dependent (or response) variable.
Example
A teacher records the hours each student studied (\(x\)) and their final exam score (\(y\)).
| Hours Studied (\(x\)) | 5 | 10 | 8 | 15 |
| Exam Score (\(y\)) | 50 | 85 | 75 | 95 |
Scatter Plots
Definition Scatter Plot
A scatter plot is a graph that displays bivariate data as a collection of points in the Cartesian plane. The independent (explanatory) variable is plotted on the horizontal axis (\(x\)-axis), and the dependent (response) variable is plotted on the vertical axis (\(y\)-axis).
A scatter plot is the primary tool for visually identifying a potential relationship, or correlation, between two quantitative variables.
Method Constructing a Scatter Plot
- Identify Variables: Determine which variable is independent (\(x\)) and which is dependent (\(y\)).
- Set Up the Axes: Draw and label the horizontal axis for the \(x\)-variable and the vertical axis for the \(y\)-variable. Choose appropriate scales for both axes that cover the range of the data.
- Plot the Points: For each pair of (\(x, y\)) values in your dataset, plot a single point on the graph at the corresponding coordinates.
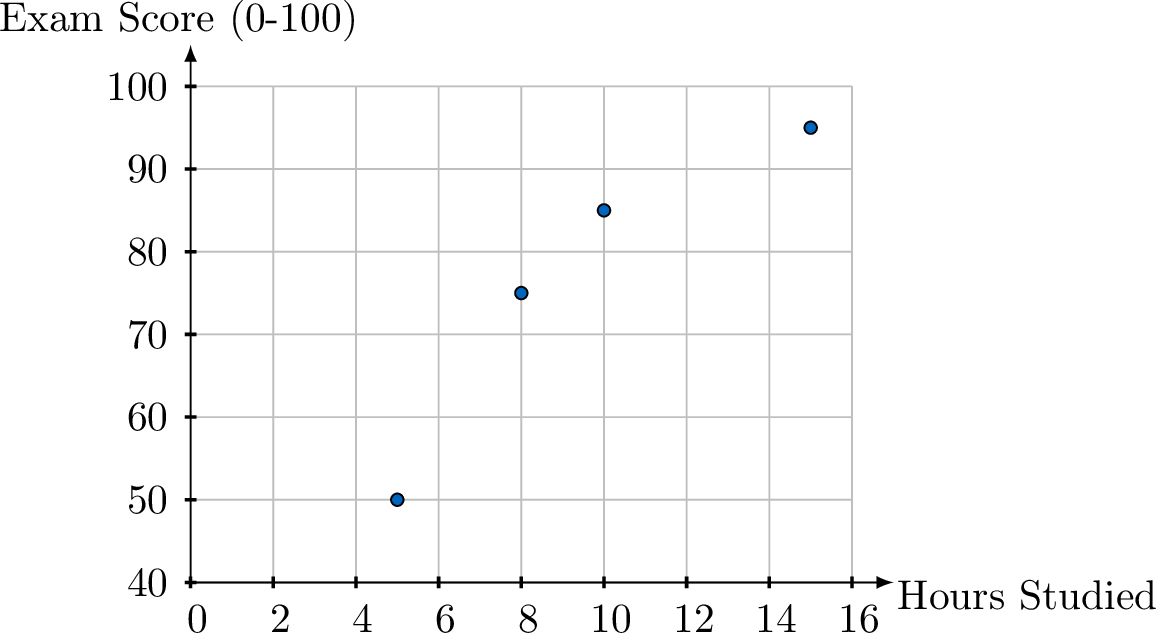
Example
A teacher recorded the number of hours students studied and their corresponding exam scores. The data is shown below:
| Hours Studied (\(x\)) | 5 | 10 | 8 | 15 |
| Exam Score (\(y\)) | 50 | 85 | 75 | 95 |
- Variables: "Hours Studied" is the independent variable (\(x\)) and "Exam Score" is the dependent variable (\(y\)).
- Axes: The x-axis will be labeled "Hours Studied" and the y-axis will be "Exam Score". The scales must accommodate the data ranges.
- Plot Points: We plot the four coordinate pairs: (5, 50), (10, 85), (8, 75), and (15, 95).
Correlation
Definition Correlation
Correlation describes the nature of the relationship between two quantitative variables.
Definition Direction: Positive or Negative
The direction describes the overall trend of the data.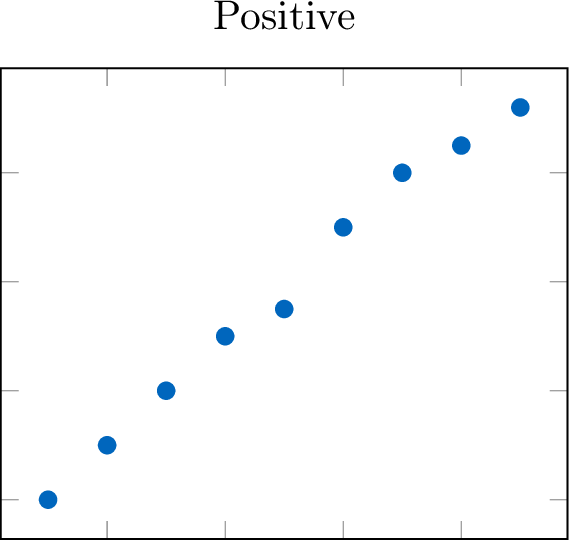 \quad
\quad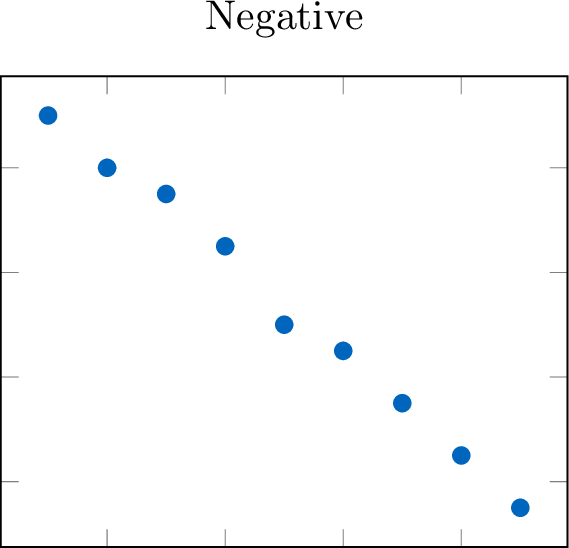
- Positive: As the independent variable (\(x\)) increases, the dependent variable (\(y\)) tends to increase. The points trend upward.
- Negative: As the independent variable (\(x\)) increases, the dependent variable (\(y\)) tends to decrease. The points trend downward.
\quad
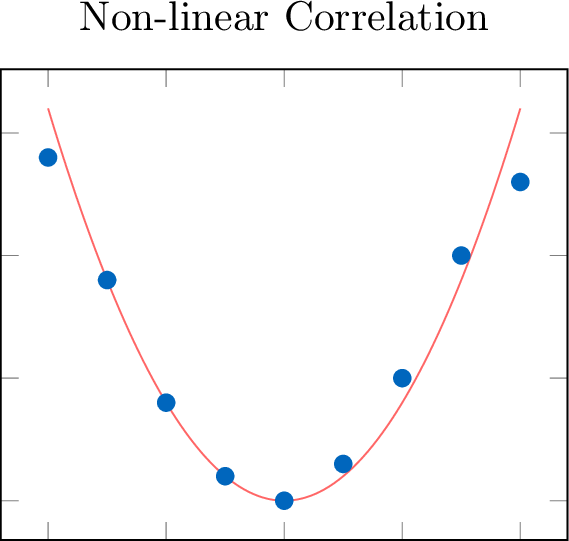
Definition Form: Linear or Non-linear
The form of the relationship is linear if the data points appear to follow a straight-line pattern. If they follow a curve other than a straight line, the form is non-linear.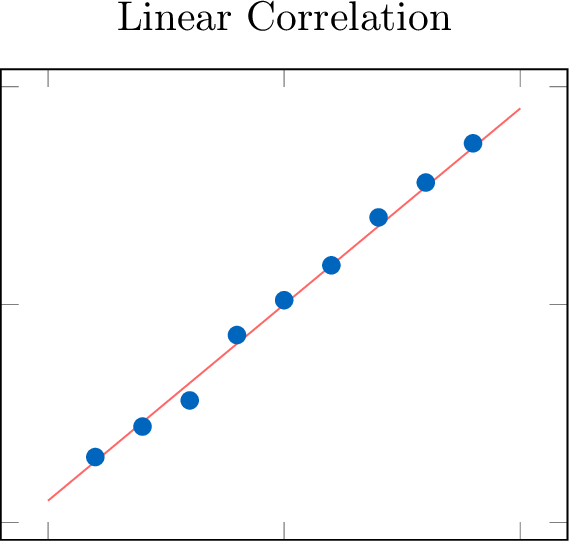
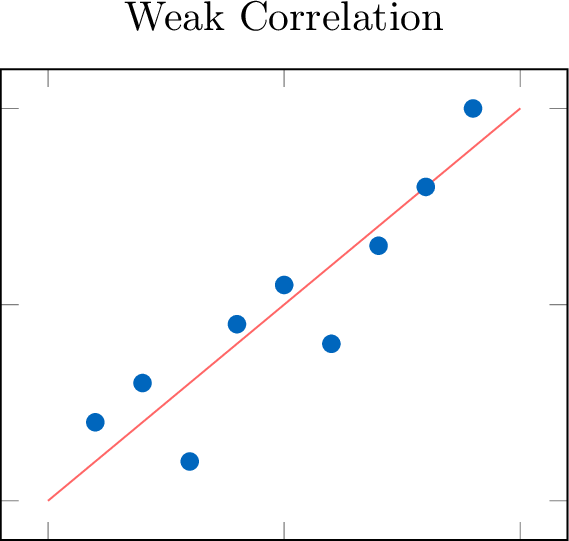
Definition Strength
The strength of a correlation describes how closely the data points adhere to the identified form.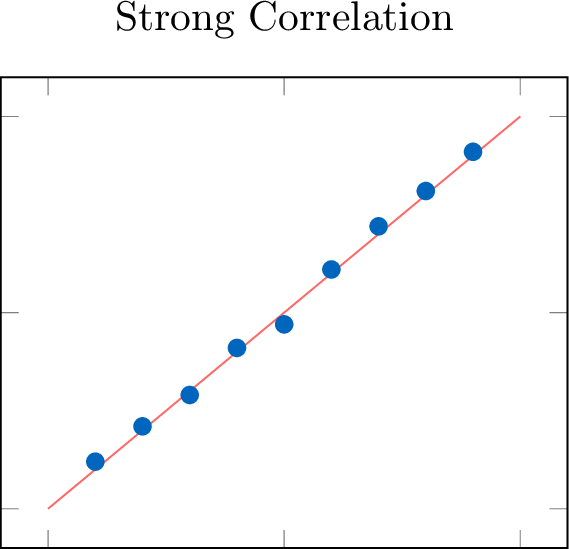
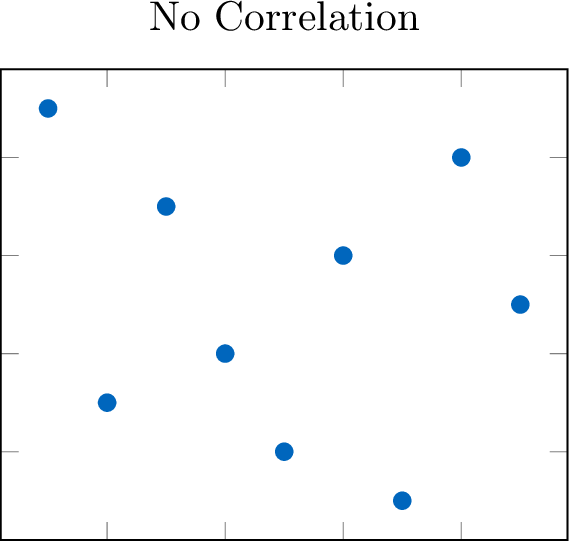
Definition Outliers
An outlier is a data point that deviates significantly from the main pattern of the data.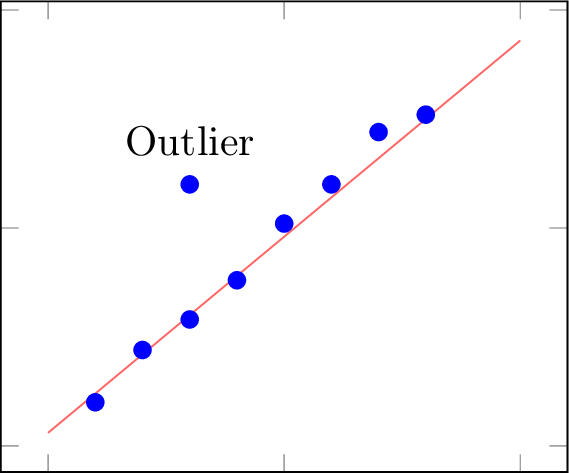
Method Describing a Correlation
When asked to describe the relationship shown in a scatter plot, you should always comment on all four features in a concise statement.
- Direction: Is it positive or negative?
- Form: Is it linear or non-linear?
- Strength: Is it strong, moderate, or weak?
- Outliers: Are there any notable outliers?
Example
Describe the correlation between hours studied and exam scores shown in this scatter plot.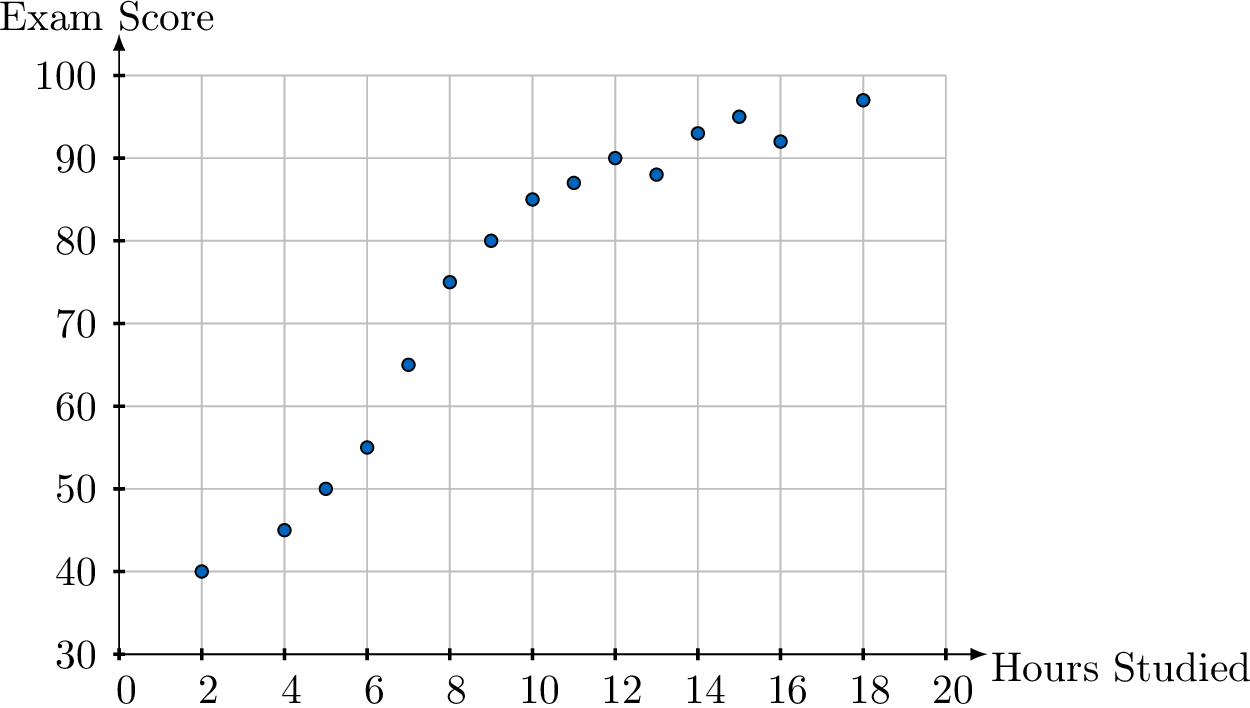
There appears to be a strong, positive, linear correlation between hours studied and exam scores. As the number of hours studied increases, the exam score tends to increase in a straight-line pattern. There are no obvious outliers.
Correlation vs. Causation
Correlation Does Not Imply Causation
Observing a statistical relationship (correlation) between two variables, \(x\) and \(y\), is not sufficient evidence to conclude that a change in \(x\) causes a change in \(y\).
Definition Causation
Causation exists only if a change in the independent variable is shown to directly cause a change in the dependent variable. Proving causation requires a carefully designed controlled experiment, not just observational data.
Definition Confounding Variable
Often, a correlation between two variables (\(x\) and \(y\)) is actually caused by a third, unobserved factor known as a confounding variable (\(z\)). This variable influences both \(x\) and \(y\), creating an apparent but misleading relationship between them.
Example
Data shows a strong positive correlation between ice cream sales and the number of people who get sunburned.
Does this mean eating ice cream causes sunburn? If not, identify the relationships and the likely confounding variable.
Does this mean eating ice cream causes sunburn? If not, identify the relationships and the likely confounding variable.
No, eating ice cream does not cause sunburn.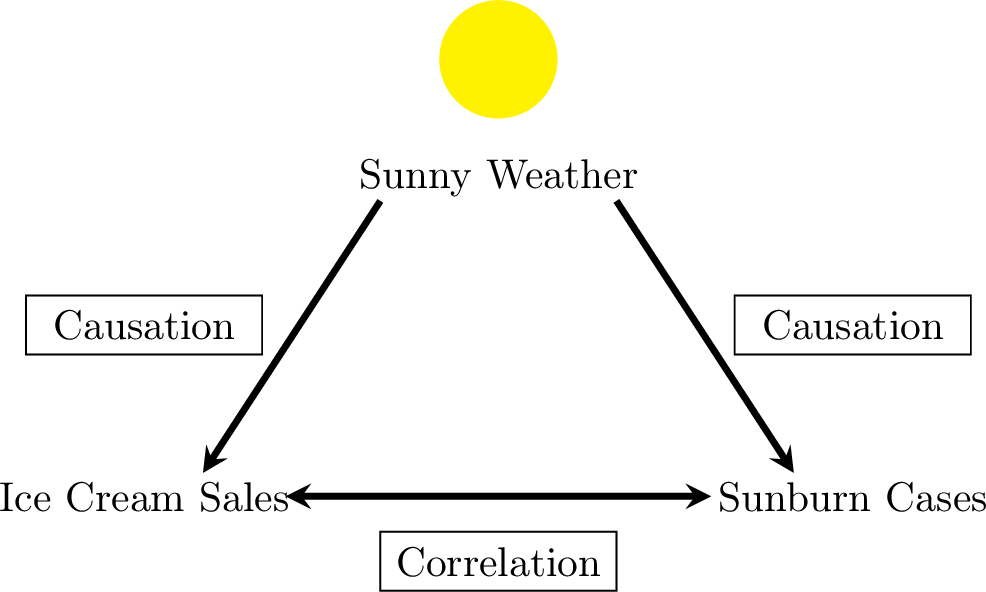
- The relationship between ice cream sales and sunburn cases is a correlation, not causation.
- The likely confounding variable is Sunny Weather. Hot and sunny days cause an increase in ice cream sales and also cause an increase in people getting sunburned.
Measuring Linear Correlation
While scatter plots allow us to visually describe a correlation, this assessment is subjective. To provide a precise and objective measure of the strength and direction of a linear relationship, we use numerical coefficients.
Definition Pearson's Correlation Coefficient (\(r\))
The Pearson correlation coefficient, denoted by \(r\), is a measure of the linear correlation between two sets of data. It is defined as the ratio of the covariance of the two variables to the product of their standard deviations:$$ r = \frac{\text{cov}(x,y)}{\sigma_x \sigma_y} $$where \(\text{cov}(x,y)\) is the covariance and \(\sigma_x\), \(\sigma_y\) are the standard deviations of \(x\) and \(y\).
Method Using technology to calculate
In practice, calculating \(r\) by hand is tedious for large datasets. We use a Graphic Display Calculator (GDC) or statistical software.
- Enter the bivariate data into two lists (e.g., List 1 for \(x\) and List 2 for \(y\)).
- Select the linear regression calculation (often labeled \texttt{LinReg(ax+b)} or similar).
- Read the value of \(r\) displayed on the screen. (Note: On some calculators, you may need to turn "Diagnostics On" to see \(r\)).
Proposition Properties of Pearson's Correlation Coefficient (\(r\))
The Pearson's correlation coefficient (\(r\)) is a value in the range \([-1, 1]\) that quantifies the direction and strength of a linear relationship between two quantitative variables.
- The sign of \(r\) indicates the direction (positive or negative).
- The magnitude (absolute value) of \(r\) indicates the strength. An \(|r|\) value close to 1 implies a strong linear correlation, while a value close to 0 implies a weak or no linear correlation.
| Value of \(|r|\) | Strength of Correlation |
| \(|r| = 1\) | Perfect |
| \(0.9 \le |r| < 1\) | Very Strong |
| \(0.7 \le |r| < 0.9\) | Strong |
| \(0.5 \le |r| < 0.7\) | Moderate |
| \(0.3 \le |r| < 0.5\) | Weak |
| \(0 \le |r| < 0.3\) | Very Weak or None |
Linear Regression
When a scatter plot indicates a linear correlation between two variables, we can model this relationship using a straight line. This line, known as the regression line, can be used to make predictions. The reliability of this model is often assessed using the coefficient of determination (\(r^2\)). A high \(r^2\) value indicates that a large proportion of the variance in the dependent variable is explained by the independent variable, suggesting the linear model is a good fit for the data.
Definition Least Squares Regression Line
The least squares regression line, written as \(y = ax + b\), is the unique line of best fit that models the linear relationship between \(x\) and \(y\). It is calculated by minimizing the sum of the squares of the residuals.
A residual is the vertical distance between an observed data point \((x_i, y_i)\) and the predicted point on the regression line \((x_i, \hat{y}_i)\).$$ \text{Residual} = \text{observed } y - \text{predicted } y = y_i - \hat{y}_i $$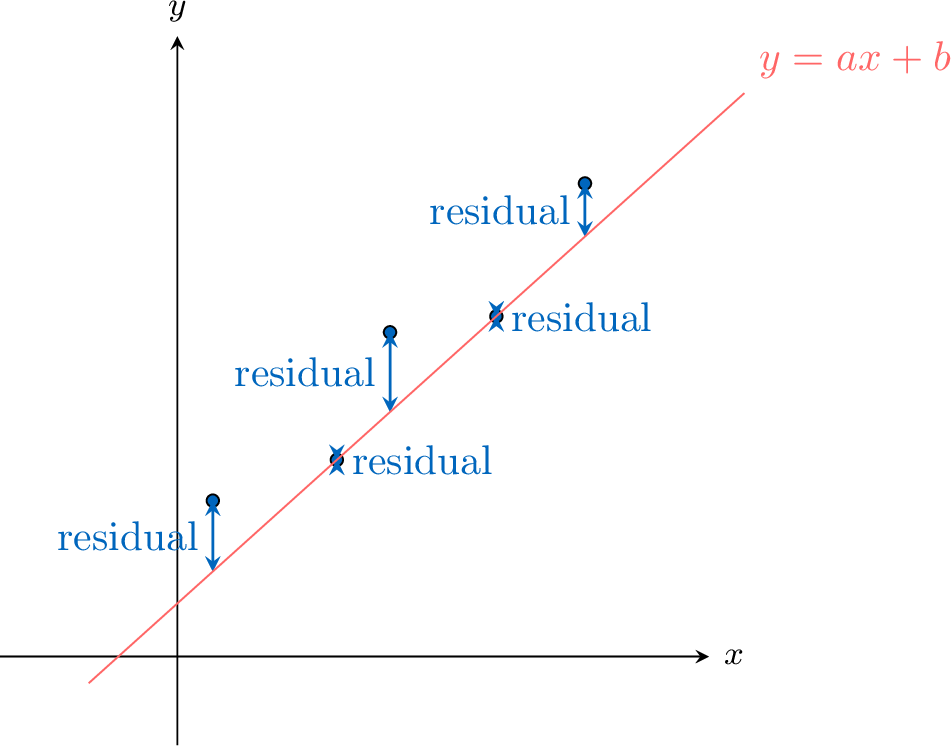
A residual is the vertical distance between an observed data point \((x_i, y_i)\) and the predicted point on the regression line \((x_i, \hat{y}_i)\).$$ \text{Residual} = \text{observed } y - \text{predicted } y = y_i - \hat{y}_i $$
Method Calculating Regression Coefficients
In practice, specifically for large datasets, the equation of the regression line is determined using the statistical functions of a calculator (GDC) or software. However, it is possible to calculate the coefficients manually using summary statistics.
A fundamental property of the least squares regression line is its relationship with the arithmetic means of the data sets. This property is frequently used to find missing variables without needing the full dataset.
Proposition Mean Point
The least squares regression line (\(y = ax + b\)) passes through the point defined by the mean of the \(x\)-values and the mean of the \(y\)-values: \((\bar{x}, \bar{y})\).$$ \bar{y} = a\bar{x} + b $$
Example
The average weekly study time and the final mathematics test score for a selection of students are shown below:
| Study Time (\(x\) hours) | 2 | 5 | 1 | 7 | 4 | 9 | 6 | 3 |
| Test Score (\(y\) marks) | 45 | 65 | 30 | 85 | 60 | 95 | 70 | 55 |
- Construct a scatter diagram to illustrate the data.
- Find the equation of the regression line \(y\) on \(x\). State and interpret its gradient in the context of the problem.
- Estimate the test score for a student who studies for 8 hours per week.
- Estimate the weekly study time for a student who scores 40 marks.
- Scatter Diagram:
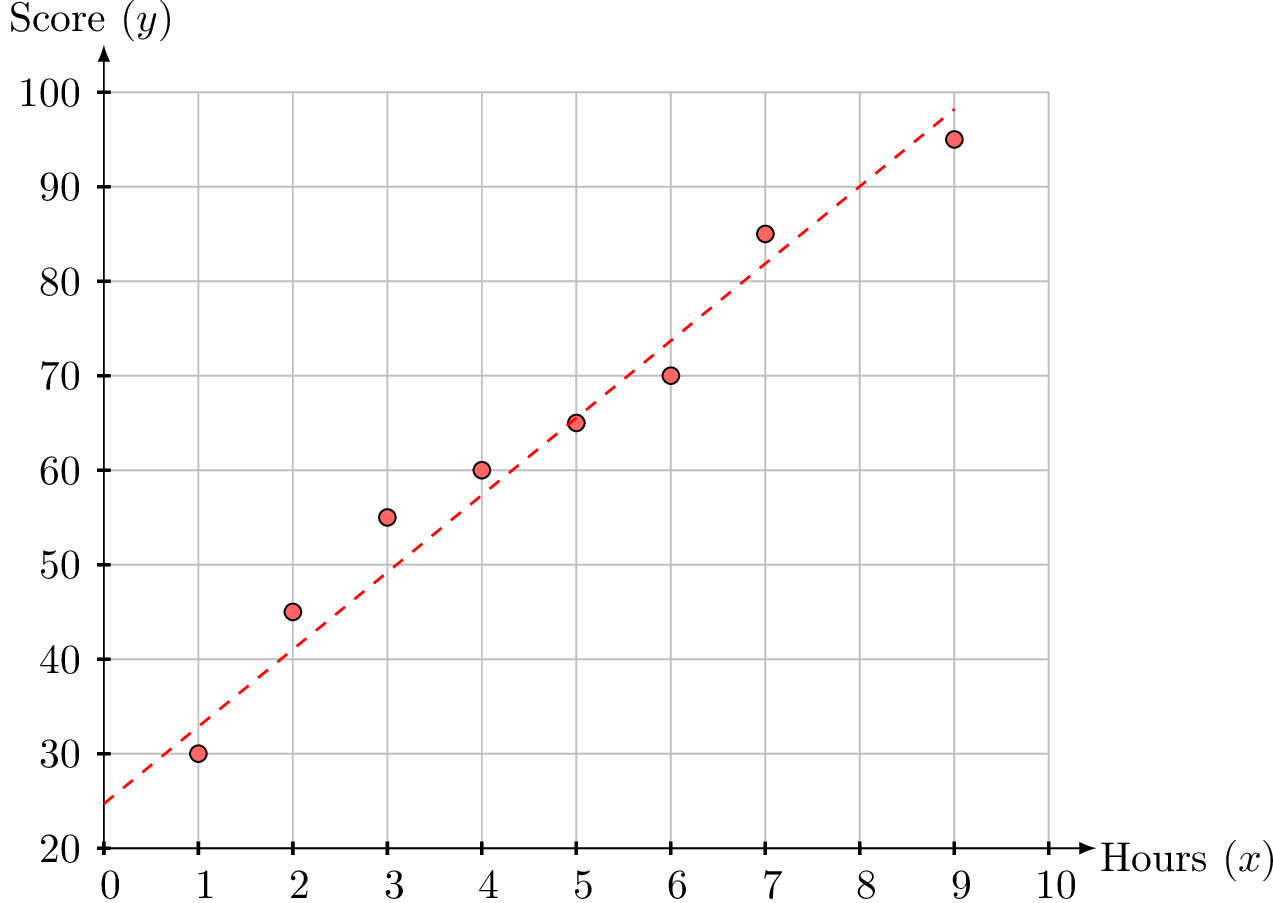
- Regression Line:
Using a calculator, the equation is approximately: $$y = 8.17x + 24.7$$ Interpretation:
The gradient is \(8.17\). This means that for every additional hour spent studying per week, the test score increases by approximately 8.17 marks on average. - Estimation (Score for 8 hours):
Substitute \(x = 8\) into the equation: $$y = 8.17(8) + 24.7 = 90.06$$ The estimated score is roughly 90 marks. - Estimation (Time for 40 marks):
Substitute \(y = 40\) into the equation: $$40 = 8.17x + 24.7$$ $$15.3 = 8.17x$$ $$x \approx 1.87$$ The estimated study time is roughly 1.9 hours.